
How an LLM Changes its Mind
Safety and efficiency with universal approximators and Turing machines

Deep neural networks are unlocking solutions to new classes of problems seemingly on a monthly or weekly basis. The capabilities of LLMs, coding assistants, and agents are very impressive, but it’s also easy to get a bit carried away about what they are actually doing when they are provocatively referred to as artificial intelligence. They are still algorithms, and it’s good to take a step back to look at the type of algorithm they actually are.
Fortunately, we know a lot about what deep neural networks represent. As a starting point, the universal approximation theorem (UAT) says that a feed-forward neural network with at least one hidden layer can approximate any continuous function over a compact domain to any desired degree of accuracy, provided it has enough neurons and a non-linear activation function.
This begs a number of follow-up questions:
What kinds of tasks are (not) solved by approximating a continuous function?
For this purpose, are transformers equivalent to feedforward neural networks, or do they do something different?
How do these map to computational hardware, like CPUs, GPUs, or NPUs?
Answering these questions requires a review of what “computation” means, looking all the way back to the writings of Turing, Minsky, and Chomsky. In exchange we get some insights into the versatility as well as the energetic cost of current AI.
I’ll provide some answers to the first two questions in this post, and a detailed look at the last one in a follow-up.
Universal Approximation
The prototypical “feedforward neural network” from the UAT is a multi-layer perceptron (MLP). This is typically composed of linear layers (which multiply its inputs by a weighting matrix) and a nonlinear activation function.
In the plots below1, we’re approximating a quasi-sinusoidal curve on the left and a square wave on the right using an MLP.
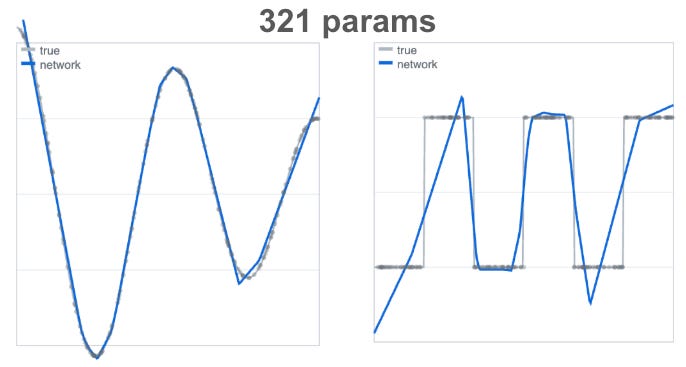
With larger model width and depth:
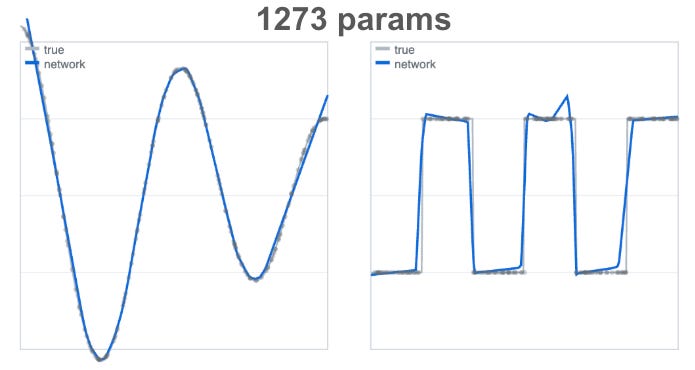
You’ll notice that the square wave is much more difficult to approximate than the sinusoidal one. Why is that? If you recall from above, the UAT promised that the MLP would be good at approximating continuous functions, and the square wave has periodic discontinuities.
Before you think that this is some pedantic example that would never occur in practice, let me offer two more practical ones that are equivalent.
Suppose you have a drone flying through a forest of tall trees:
The task is obstacle avoidance: the input is the front camera view, and the output we’d like is a path that won’t collide with a tree. In such a view, if the view changes continuously in such a way that a path becomes too narrow to pass through, the safe path must jump to a different one discontinuously.
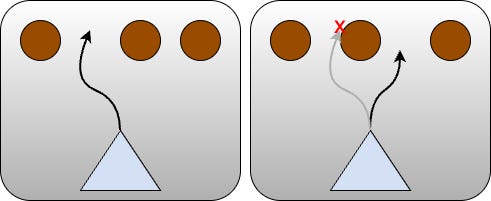
An MLP would need to sample the input space very densely to quickly interpolate between the left path and the right one (as in the square wave example above). This has a high model size penalty, and additionally needs to interpolate through an unsafe part of the output space.
Another practical example is related to the title of the article. Assuming an LLM’s output is a token view of an internal reasoning state, “changing its mind” on a yes / no question requires a similar jump in its state. However, the internal computing machinery of a modern LLM, the transformer, is more complex than an MLP. We’ll look into the two categories separately below.
Lookup Tables to Turing Machines
The computation power guaranteed by the UAT is equivalent to a lookup table. A lookup table effectively pairs inputs and outputs so that it can “look up” the appropriate output when queried with an input. In continuous spaces, this can include some interpolation or extrapolation. The curve approximation figure above is a good visualization of this: the table would contain {x, y} entries. The compact domain condition of the UAT effectively ensures that the number of entries in the lookup table is finite.
On the other end of complexity, we have a Turing machine: an automaton that has access to unbounded memory, and is able to make discrete decisions based on what is in its memory. While this may sound foreign, it is actually a very familiar concept. A CPU paired with almost any programming language is a Turing machine (putting aside the implementation detail of potentially running out of memory). You can control a program’s flow using if, while, etc. and call subroutines, and with these building blocks, you can build any software that has ever been written.
It should be clear that a Turing machine can do fundamentally more than a lookup table:
It can process an input that is arbitrarily large, which a lookup table cannot do. For example, you can very easily write a CPU program that factorizes an integer, but we could never fit such an algorithm on a lookup table, since you could always input a larger integer. A more current example is a pre-transformer language model, which could not handle sequences of arbitrary length, and thus could not exhibit the level of capability we got with a GPT.
It can exhibit irregular flow control, like branching and jumping. In the “flying through forest” example above, it can do something like
if left_path_too_narrow:
take_right_path()
else:
take_left_path()While this looks benign, it is deeply connected to the continuity clause of the UAT. An MLP cannot represent an algorithm that needs this kind of branching to have a discontinuous or symbolic jump.
In the example above, a square wave was still able to be approximated by an MLP, but at the expense of a large number of parameters. As a contrast, here’s an almost trivial program that could accomplish the requisite classification with very few parameters:
if x mod 2 < 1: # if the remainder of x/2 is < 1
return 1
else:
return -1This shows the expressive power of a Turing machine compared to a lookup table. Adding a little structural or organizational complexity drastically reduced the number of required parameters.
The Transformer Attention Mechanism
We discussed earlier how the UAT only addresses a finite set of inputs. This is true in practice for MLPs as well: it will typically be used to process a fixed image size, or in an transformer feedforward network, a fixed layer width.2
The attention mechanism of transformers is different. In an LLM, when a sequence of tokens is fed in, each token can attend to each other token, enabling a computation paradigm that can handle sequences of arbitrary length. This makes it different from a lookup table, because the input dimension itself is unbounded. You don’t need to retrain for longer sequences since the attention mechanism adapts the algorithm.
In practical terms, a transformer’s sequence length has to be limited to a maximum context length to manage the mapping to computational hardware. By the same token, CPUs also needed unbounded memory to be true Turing machines.
So, are implementable transformers, like general purpose CPU programs, Turing machines in all but the most pedantic terms?
Not quite — there’s still a fundamental gap that cannot be closed. Transformers are still continuous function approximators and cannot efficiently exhibit irregular flow control. A 2026 paper from Oracle AI looks at discrete reasoning with transformers, and I’ll let it speak for itself:
Through this synthesis, we provide readers with a cohesive understanding of why transformers succeed in interpolation tasks (e.g. summarization) but fall short in reliably executing symbolic algorithms.
Symbolic algorithms are characterized by discontinuous outputs that present a challenge to transformers. Like in the square wave example above, you can try to circumvent the issue by increasing model width or dataset size, but this comes at the cost of greatly increased model size and inefficiency. Moreover, as the paper points out, as you compose symbolic tasks (task A → task B → …) the number of switching boundaries grows combinatorially.
For an LLM to change its mind on a yes / no answer, architecturally it needs to continuously interpolate through reasoning trajectories, traversed by generating (lots of) reasoning tokens.
Closing Thoughts
Deep neural networks can solve a huge variety of problems, founded on their universal function approximation ability. Transformers’ ability to process arbitrary sequences advances them into a new computational category beyond lookup tables.
However, they are still not well suited to problems with symbolic or discontinuous outputs. This is common in problems to do with safety or symbolic reasoning. In current successes of deep learning, solutions to these kinds of problems are attained in a similar fashion as the square wave approximation above — it works, but is extremely inefficient.
These problems could potentially be solved with much smaller models if they had Turing machine-style universal computation capabilities. Devansh’s article linked below advocates for the same thing, approaching it from the computational hardware perspective for some classes of problems. In a follow up post, I’ll tie together the first-principles analysis in this post to current computational hardware, to discuss how different algorithm classes effectively map.
Thanks for reading!
If you enjoyed this post, please like (❤️) and restack — it helps others find my writing. Subscribe to receive new posts. All of this is greatly appreciated.
References and Further Reading
Are Transformers Turing-complete? — Hessam Akhlaghpour (2024)
Barriers to Discrete Reasoning with Transformers — Oracle AI (2026)

For a gentle introduction to transformers with a computer architecture framing, I’d recommend Vik’s article.
I liked the insight. We should think twice before throwing neural network at the problem and having inefficient solutions.