
A coding agent equivalent for robotics pipelines
Part 4: Closing the action loop with a VLA vs. a spatial VLM "agent"

This article is part of a series on end-to-end robotics pipelines
In this part, we finally close the loop to get our WidowX robot arm in the MuJoCo simulation to execute some manipulation tasks. I’ll go over how to build up (from scratch) something like the following behavior from a text prompt, and what we can learn about the architecture of robotics pipelines in the process.
Result of “Place the red block on the blue target”:
An end-to-end Vision-Language-Action (VLA) model is the obvious modern technology researchers and companies are moving toward for this kind of functionality, and part 3 of this series was dedicated to understanding them from the inside. The deployment exercise for this part made clear that a small VLA’s failure modes are difficult—to the point of impossible—to eliminate without retraining.
That observation ultimately forced a pivot to a different architecture, where the flexible programming and semantic reasoning layer delegates physical grounding to explicitly separate tools. This post explains how that architecture works, and what it says about robotics pipelines more broadly.
In addition to the story, all the code is open-source — feel free to learn from, star, and fork! Also, if you like this kind of post, please like, share, and subscribe:
Moravec’s paradox and VLAs: control bandwidth problem
In the previous post, we spent some time interpreting the perception and language understanding in VLAs — specifically, the Vision and Language parts. In many ways, the action head exhibits the most architectural diversity in VLAs.
There are broadly two types of action heads. (Auto)-regressive action heads generate actions sequentially, one at a time. This is similar to how most LLMs work today, generating tokens one after the other. Generative (or diffusion / flow-matching) action heads, in contrast, generate a whole action sequence at a time and incrementally refine it, similar to diffusion-based image generators.
Regressive action generators have a fundamental difficulty when used for behavior cloning in continuous action spaces. As Max Simchowitz presents in his recent CMU RI seminar1, the issue is that a small deviation takes the red robot trajectory off the training (expert) demonstration distribution, and it is unable to recover.

The same problem doesn’t occur in discrete spaces (like text generation) because they can be trained with a 0-1 or cross-entropy loss function, encouraging very aggressive contraction to the training distribution. Simchowitz identifies this challenge in continuous spaces with Moravec’s paradox (why learning hasn’t been as effective in physical tasks as in symbolic tasks like language).
Action chunking2 presents a way to get around this problem. By producing an action sequence, over which the natural dynamics of the system is assumed to prevent compounding error, the rate of divergence is kept under control:
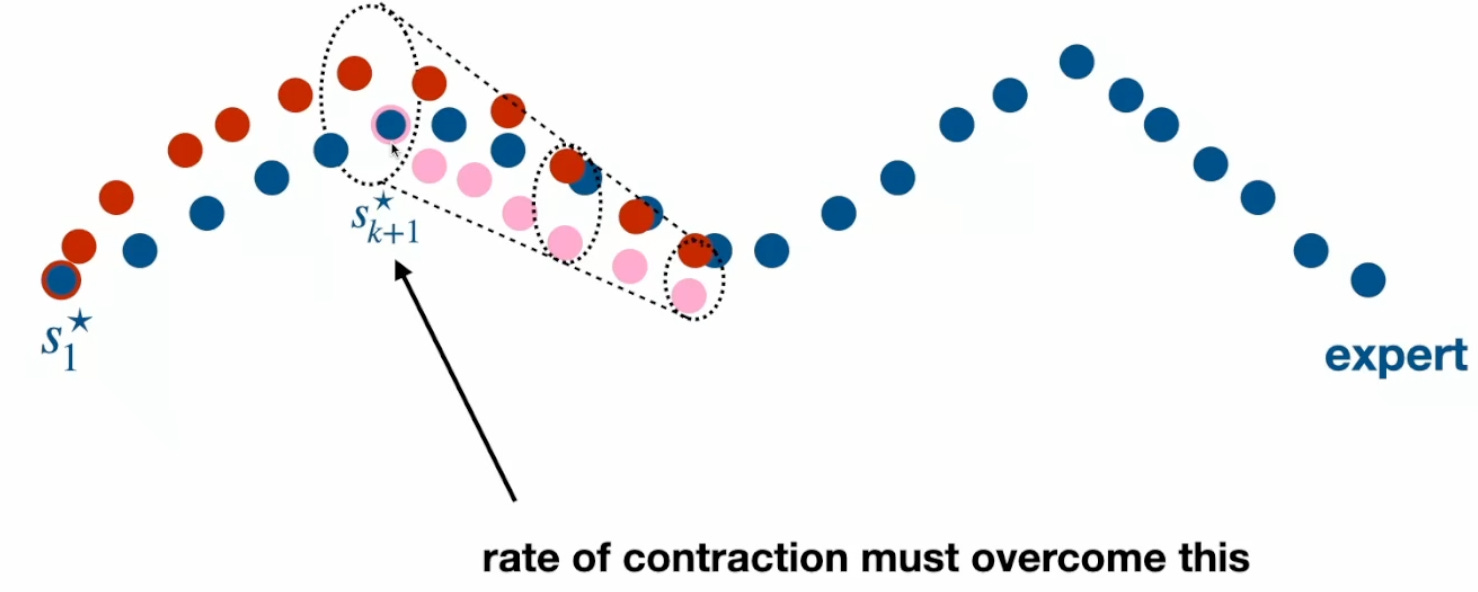
A key assumption there was that the underlying system needs to have some strong stability properties. I won’t go into definitions here, but in practice, this means that VLA actions are almost exclusively desired positions (as opposed to velocity or torque). More generally, this means that the behavior is what is called “quasi-static”, i.e. the robot goes through a sequence of statically stable configurations. As an aside, this is also why VLA-implemented manipulation behaviors are slow and wouldn’t apply to dynamic behaviors like agile locomotion; quoting this Quanta magazine article, “Atlas moves like molasses while grasping auto parts but glides like a gymnast when it’s not touching anything except the floor”.
So, action chunking is a way to address the control bandwidth problem from part 1 for regressive policies. Generative action heads don’t have the same inherent divergence issue, and it does seem like in practice most VLAs use that strategy — this also applies to our demo setup with X-VLA from part 3. They learn a distribution over actions, and at inference time, start with a pure “noise” action and iteratively denoise it. One thing to note is that the trajectory horizon does not impact how long the inference takes (it is just the size of the action distribution learned during training). This means that shortening the action horizon size in order to get faster results isn’t an option like it typically is in model-predictive control.
Now that we understand VLA action heads a little better, let’s move on to closing the action loop.
Closing the loop with X-VLA: generalization and separation problems
The VLA outputs action chunks (a sequence of desired poses), and we now need to control the motors to reach them. The model for the WidowX arm in our simulation is set up for position control on the joints. This is in part due to how most people are using this arm (in some cases due to algorithmic constraints as mentioned above). For this article, I chose to keep that as is, and as a first pass, implement the most reasonable control method in this situation: inverse kinematics (IK). The implementation uses gradient descent to iteratively find the joint angles that reach a certain pose. This is a generalizable and quick method that will probably get replaced in the last part of the series by a non-IK solution.
After closing the control loop, prompting the VLA to “pick up the red block”, and running the simulation — well, it didn’t work. At this point, it was a little bit of the same challenge of “black box debugging” as in part 3, but now with more (literal) moving pieces.
It’s important to remember that X-VLA is a small VLA, and its generalization capabilities are limited by model size. As we saw in part 3, the model’s spatial reasoning (how far to reach, when to close) is tightly coupled to the training camera viewpoints. The camera intrinsic and extrinsic parameters are wrapped up in the full X-VLA policy and not separable3, and so I tried to modify the images received by the policy to try and match the training dataset.
I went into the BridgeData training dataset, and found the most similar task in the training data, grabbed the training video, and tried to make my scene resemble it as closely as possible. To do this, I manually tuned the camera position, robot gripper initial pose and framing (camera extrinsics), image field of view (intrinsics), aspect ratio “squishing” to match training data, lighting / shadows, table appearance:

Unfortunately, despite the manual tuning, and also completely decluttering the scene, the policy didn’t succeed with the prompt “Pick up the red block”:
It consistently overshot the block, which indicated to me that the visual processing had a consistent error, but fiddling with the camera settings didn’t yield a better result. The structural issue with VLAs (non-separability of camera and kinematics parameters) makes this debugging quite challenging, even beyond the techniques from part 3. If you know of anything that could have gotten this to work, let me know in the comments!
I suspect that the generalization abilities of this size of VLA are just not sufficient to be able to use the policy zero-shot. There are two reasons why that is a roadblock: First (isolated to my usage here), I didn’t have a leader-follower arm or space mouse to collect more training data and go through a fine-tuning process. The second (and more fundamental) issue is that this limits how this kind of strategy can be used by robot end-users in ad-hoc unknown environments.
The flexible task programming and semantic task understanding of VLAs were some of the motivations for this project. Is there an alternative solution that can keep those strengths while adding some needed structure?
An “agentic” modular alternative
For scene and task understanding combined with flexible programming, we need some kind of VLM, but is there a way to get information out of the VLM in a more structured way?
In late 2025, Google released Gemini Robotics 1.5, which consists of two models designed to have a hierarchical interface:
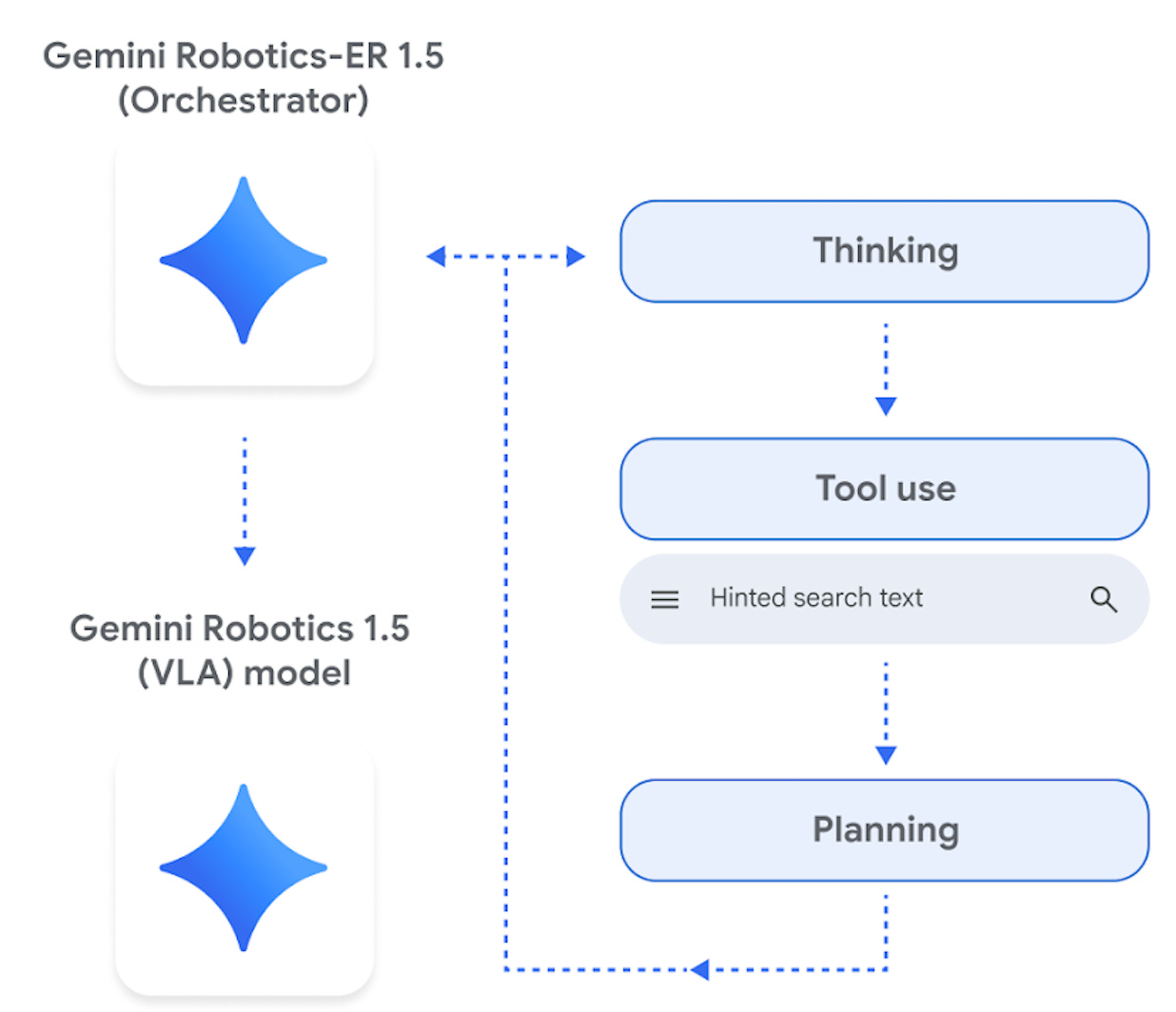
Out of the two, I only used the ER (Embodied Reasoning) model, which has been trained to output structured text combining the spatial understanding and function calling capabilities of the impressive Gemini model family. As documented here, the “pointing” feature is effectively a customizable vision processing pipeline, and I found it to be incredibly robust:

The function calling capabilities can also be used to break down complex tasks into sub-steps, which is what I used for the working demo in the first section of this article. Here you can see that it is flexible to different prompts with no other changes:
Most shockingly, I spent only a couple of hours with the Gemini models to get to the successful end result above, after unsuccessful attempts over a significantly longer period with X-VLA.
So, why does this work so much more easily?
Just like Simchowitz did in his RI seminar, I think I’d have a pragmatic answer to do with scale, as well as an algorithmic answer independent of it. On model size, Gemini ER 1.5 is described as achieving “the low latency of a Gemini Flash model” for spatial tasks, which suggests it's Flash-scale (~8B range) but much larger than X-VLA (0.9B). On the algorithmic side, the difficulties we ran into with the VLA often had to do with inseparability of concerns (kinematics, calibration parameters not separable from the policy), and generalizability (difficult to tell when we were out of distribution).
I think an appropriate analogy here is between an LLM (even a coding-tuned one) to a coding agent like Claude Code (an LLM in a larger system that can interact with “tools”). A coding agent doesn’t ask the LLM to emit machine code directly; it keeps the model in the semantic reasoning layer and delegates execution to existing well-understood tools. In this analogy, I’m suggesting that camera calibration, kinematics, motion controllers are tools that the VLM can benefit from interfacing with. Gemini ER just works on images; a well-defined, separable concern without introducing variability due to the robot morphology. Our known camera transformations then lift its image-space outputs into 3D. If we move the camera (impossible with X-VLA without retraining), we can simply replace the camera calibration parameters.
However, this structural separation appears to contradict the pure end-to-end view that goes back to the “bitter lesson.” Overall, in my opinion, the bitter lesson essay has been interpreted more broadly than current evidence supports, and we will continue to see reinterpretations and corrections.
Closing thoughts
In this part of our series on robotics pipelines, we demonstrated a simple setup that exhibits flexible task programming. Despite our best efforts with an end-to-end VLA, this success came from coupling a strong VLM with model-based “tools” such as camera geometry and inverse / forward kinematics. This seems to me to reflect some of the strengths of agents that interacts with tools vs. an equivalent chatbot-style LLM. It certainly provided a clean way to integrate the strengths of a large learning-based model with structured model-based methods — something I’d set as a goal in part 1 of this series.
While this is a nice result, there are still a number of limitations: Gemini’s task planning is slow, even with cloud hardware. In the current implementation, the full plan is created at startup and there is no replanning for dynamic environments. The model is also not “open” and likely an order of magnitude larger than X-VLA. In the future, I may look into what it takes to develop an “embodied reasoning” model — it seems like the Gemini ER model appears to build on the ideas of the published SpatialVLM.
In the last part of this series, I will plan to improve the lower-level controller from its naive IK implementation to show more responsive and adaptive behavior. I will also aim to publish it in a browser-runnable format so you can very easily and rapidly see the effects of different prompts. As a reminder, the code is all open-source.
If you liked this post, please like (♡), share, restack, and subscribe — it helps others find my writing.
ACT paper, whose author is a founder of Sunday Robotics, who in turn have an ACT-1 foundation model
X-VLA has a soft-prompt architecture where embodiment specific parameters are technically separated, but not in an interpretable form.