
A Multi-Robot Brain is not like a Multi-Chip ISA
"Cross-embodiment" trained policies generalize well, but is that the best solution?

We have recently seen the emergence of a number of “multi-robot brains,” or AI models that are meant to output motor commands for a variety of robot bodies. Some examples are Skild AI’s omni-bodied brain, which they argue for here, and Physical Intelligence’s pi0 and later models. The capabilities of these policies are impressive, showing signs of generalization and fault tolerance that have not been demonstrated before.
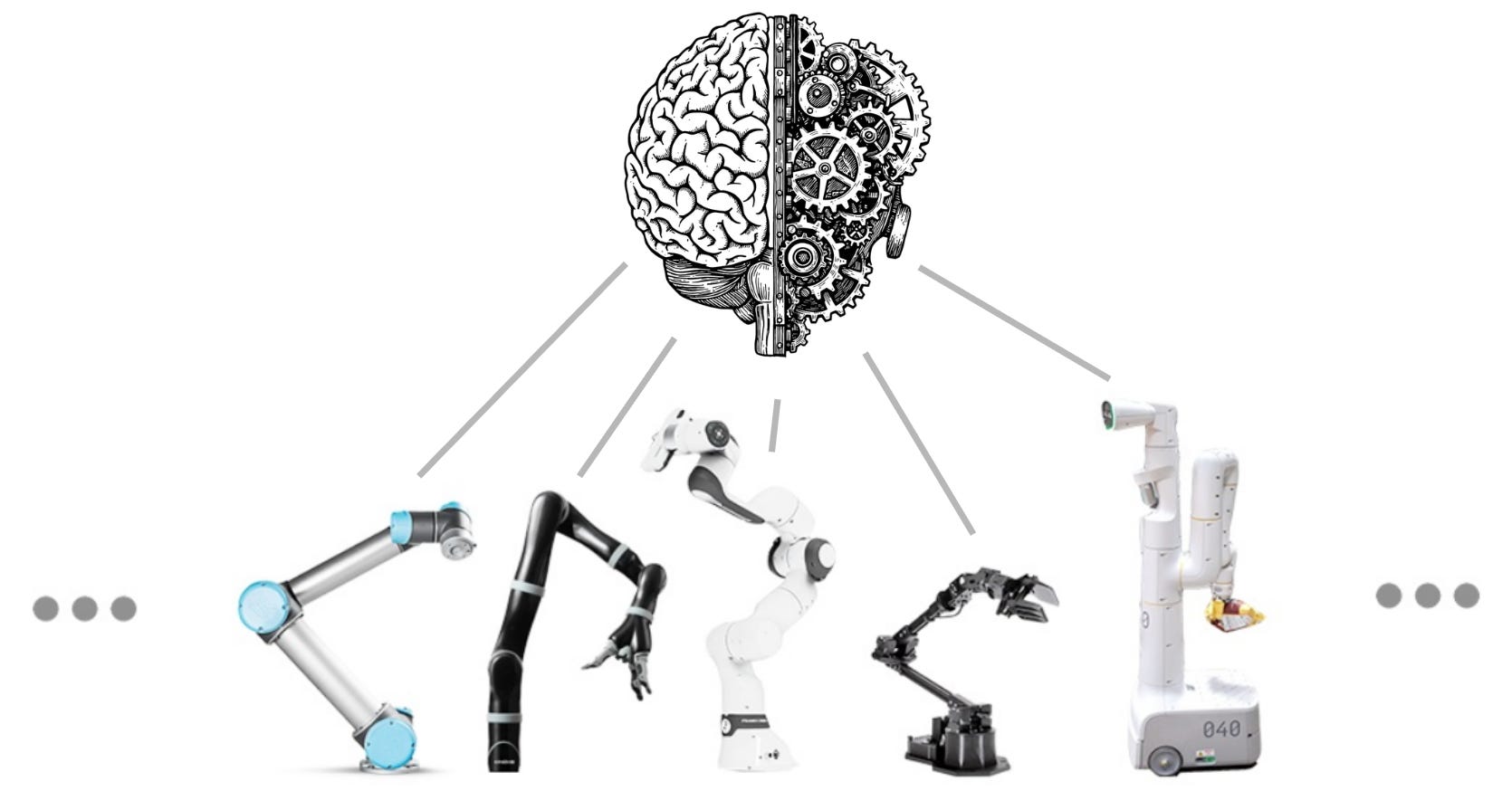
It feels natural to try and compare this kind of brain-body interface to a software-hardware interface in computers. An Instruction Set Architecture (ISA) helps abstract software programming from processor hardware implementation. The first ever ISA, in the IBM System/360 (1964), had the explicit goal of making software compatible across different hardware generations, and this goal has remained the most important driving force behind their existence.
In this article, I wanted to see how this analogy could help us think about multi-robot brains.
The ISA Analogy
The benefits of an ISA become clear when examining a typical “stack” for a computer:
The columns of this chart are different “verticals”. If a company owns every item in the column, that would be “vertical integration”. The iPhone, and most of Apple’s products, are famously vertically integrated up to the application layer. The PC ecosystem does not exhibit the same kind of vertical integration.
Conversely, “horizontal integration” is when a particular product or vendor is appears in many columns across a row of the stack. For example, the Android OS is used in 70% of smartphones sold worldwide.
The ISA allows the stack to grow horizontally without recreating every piece of the stack. The marginal effort required to introduce new software, or a new chip, is reduced as long as it can bridge itself to the ISA.
Let’s compare to a robot stack1 for a couple of hypothetical robots:
Vertical integration is exemplified by Unitree, and it could be argued that NVIDIA is positioning itself very well to be horizontally integrated as the computing device of choice.
The multi-robot brain (a) vertically bridges hardware and software, and (b) horizontally bridges different robots. In contrast, while the ISA bridges vertically, it does not bridge horizontally — the iPhone and the Android phone need not share any software or hardware components. This is an important distinction, because the horizontal bridging hinders vertical integration.
Vertical Integration
An ISA promotes vertical bridging, but simply gets out of the way after that, allowing for vertical integration. This allows for products that are really optimized to work well in a way that isn’t possible with horizontally integrated components. An easy example of this is how well sleep and wake work on a MacBook due to the tight vertical integration, and how poor it still is in Windows laptops.
The Arm AGI CPU was introduced recently because when performance is critical, companies were still building bespoke software to take advantage of vertically-integrated optimizations. Arm saw this need and it was large enough to get them to break out of a decades-old strategic choice and build their own chip (emphasis mine):
“Delivering AI experiences at global scale demands a robust and adaptable portfolio of custom silicon solutions, purpose-built to accelerate AI workloads and optimize performance across Meta’s platforms,” said Santosh Janardhan, head of infrastructure, Meta.
For critical datacenter functionality, the last mile of performance optimization needed vertical integration. Everyone else, like Amazon, Google, was already doing it by customizing their stacks, and Arm decided to try and save its customers from having to do this work by doing it themselves.
The Missing Analogue of Compilation
In computer-land, the ISA is paired with a compiler that builds a binary tailored to the target system. The compiler can optimize and produce a binary that runs well on a particular chip using vector instructions, reordering, and other optimizations within the constraints of program correctness.
There isn’t an equivalent of compilation in a multi-robot deep neural network brain (though maybe there are Turing-complete architectural alternatives that could emerge in the future). This results in a few cracks in the ISA analogy:
1) Memory / Performance
The current multi-robot brain is more like a fat binary in some ways. While the exact implementation varies, there will usually be a vector of latent variables that explicitly or implicitly encodes the details of the embodiment. So, while a Mac universal binary could use a single bit to pick x86 or Arm machine code, the robot embodiment is represented by an n-dimensional vector of latent state that can further weight or guide the network.
In the Skild AI blog post referenced above, this “fat binary” aspect is used to demonstrate recovery from limb loss, or other aspects of hardware failure. The tradeoff is the added network size, manifesting as increased memory and compute burden.
2) Hardware-Specific Optimization
A multi-robot brain needs to adapt for factors such as location and dimensions of limbs, cameras, as well as higher-level locomotion and task strategy. For the kinematics and sensor transforms, optimized code is akin to platform-specific subroutines, an analogy I made in my article series on VLAs.
A robotic behavior “compilation” step could likewise tailor task execution strategy to a particular body. For example, trajectory optimization or reinforcement learning (RL) can be used to optimize a behavior for a robot body, and like compilation, is typically done offline.
However, in a neural network multi-robot brain (which does not have this notion of compilation) designed to solve a task with B bodies, either the behavior is not optimized for each body type, or B different strategies need to be stored (bringing back the memory issue from the prior point). In reality, the multi-robot brain does store some number of distinct-looking strategies (see the Skild AI blog post for demonstrations).
However, by the nature of deep neural networks, a discontinuous divergence in strategies is not very efficiently representable. As an example of strategy discontinuity, consider that my cat needs to run or jump up human-sized stairs, whereas a larger animal could simply walk up them. The multi-robot brain needs to do a lot of work to represent effective locomotion strategies for these variations.
Common Sense Generalization
One of the main arguments in favor of cross-embodiment training is that people are finding that it really helps with generalization. For example, see this excerpt of Sergey Levine’s explanation on the Automated podcast two days ago, and Skild’s case in their blog post:
One way to do this is to train the AI to control not just one robot, but a whole multiverse of robots with different bodies. It cannot memorize the solution for one body, it must find a strategy that works across all of them. When faced with unpredictable scenarios, the AI can now use the strategies it learnt during training and keep going.
There is still ongoing research and development on this finding, but one implicit logical leap is that the strategy is being evaluated (in all these cases) with end-to-end networks. This means that the cross-embodiment training is for a deep neural network that is learning not just the particulars of one robot body, but also the functional form of the necessary mathematical transformations to control it.
As an analogy, consider training a network to perform the sine calculation,
y = f(x) := sin(x)
We don’t know what the “sin()” operation does, but we are learning it from inputs and outputs {x, y}. To train this network, we have the option of using data from one embodiment, which has x values in the range [0, 1], or data from multiple embodiments with ranges covering the range [-10, 10]. The extra data from the other embodiments are helpful to just understand how the sine function works.
Closing Thoughts
Cross-embodiment robot training creates an interesting software stack bridging software to hardware vertically, as well as horizontally across different tasks and robot bodies. The former aspect is evocative of the ISA abstraction layer in computing, but the latter aspect is more of a distinction.
I wonder if a “compilation” analogue could exist, allowing for optimization of a multi-robot policy to a slimmed-down robot-specific policy. It’s possible to use RL to post-train or to fine-tune a model such as the ones discussed in this article, but that interferes with the fault tolerance feature, and does not help reduce the model’s size.
Lastly, the size of these multi-robot policies is going to necessarily be large. Taking it to the scaling extreme, only the largest corporations may have the funding to train these models, resulting in potentially unwanted ecosystem consolidation.
To sum up, multi-robot brains have been showing impressive generalization ability, and I expect we will continue to see cutting-edge results from them. However, their generalization success is partially wrapped up with the end-to-end deep neural network architecture, and that there might be opportunities for significant optimization with architectural innovation.
Thanks for reading, and let me know your thoughts on this parallel!
If you enjoyed this post, please like (❤️) and restack — it helps others find my writing. Subscribe to receive new posts. All of this is greatly appreciated.
The stack could have been written differently to include sensors etc., but those details don’t affect the point of this article.
Another great read Avik!
A core insight for me after reading, is the multi-robot brain makes it difficult (or comparatively expensive) to verticalize. This maps well to what I'm seeing in the robotics market where a few intelligence labs are pushing the frontier of model develop and many vertical (or neo) integrators are emerging. I do wonder how verticalized robotics companies like Figure, Tesla, 1x will fair.