
Action Tokens: Fine-Grained vs. Behavioral Primitives
Why the LLM tokenization debate matters for physical AI, and what biology tells us

When Claude Opus 4.7 got released, it got some backlash from people who noticed that it was using up tokens faster for their tasks. The cause of this was a new tokenizer that would use more tokens for the same query or response.

Users were similarly upset when Opus 4.8 would use up tokens for reasoning, costing $$ while not producing any actionable output:
More broadly, as LLMs continue to gain use, the answers to many questions seem to return to tokens. Q: How responsive is an LLM? A: tokens/second. Q: How much do you spend on your LLM? A: $/token.
In this article, we will go over:
What tokens and tokenizers are in LLMs, and what the fundamental tradeoffs are (in algorithm characteristics, computation, and memory) that tokens induce.
How this tradeoff is going to be even more central in robotics or physical AI, and where biology lies on the spectrum
There is also a very interesting parallel between an action token in robotics to an instruction in computing, and the juxtaposition it creates with the RISC vs. CISC debate. I’ll cover that in a follow-on post that I’m excited to write — make sure to subscribe to get it in your app or inbox:
Tokens in LLMs
In LLMs, tokens are a numerical encoding of language. I’ll describe the tokenization process briefly here for the purposes of this article, with references to a fuller analysis in the TinyTorch course notes.
One idea is to make a word a token. That’s more or less how humans learn a language: a dictionary will have entries corresponding to words.
Neural networks process numbers, not text. When you pass the string “Hello” to a model, it must first become a sequence of integers. This transformation happens in four steps: split text into tokens (units of meaning), build a vocabulary mapping each unique token to an integer ID, encode text by looking up each token’s ID, and enable decoding to reconstruct the original text from IDs.
The tokenization process decides how the “split” step happens, and this can be done in various ways.
The simplest approach treats each character as a token. Consider the word “hello”: split into characters
['h', 'e', 'l', 'l', 'o'], build a vocabulary with IDs{'h': 1, 'e': 2, 'l': 3, 'o': 4}, encode to[1, 2, 3, 3, 4], and decode back by reversing the lookup.
Even at this point, some of the tradeoffs are becoming clear. This mapping (which is used in the forward direction for encoding, and in reverse direction for decoding) needs to somehow be stored in memory:
Character vocabularies are tiny (typically 50-200 tokens depending on language), which means small embedding tables. A 100-character vocabulary with 512-dimensional embeddings requires only 51,200 parameters, about 200 KB of memory. This is dramatically smaller than word-level vocabularies with 100,000+ entries.
However, a different problem arises when it comes time to actually process the encoded sequence. This processing is algorithm-dependent (more on this later). When an LLM receives a query, it will pass through a transformer block that receives the token sequence. The length of this sequence has a huge impact on the number of computations in the transformer.
Character tokenization has a fatal flaw for neural networks: sequences are too long. A 50-word sentence might produce 250 character tokens. Processing 250 tokens through self-attention layers is computationally expensive, and the model must learn to compose characters into words from scratch.
So, small vocabularies mean low memory usage for the dictionary, but long sequences for computation. Large vocabularies (like full words) have high memory usage, but produce shorter sequences.
The last sentence in the quote above brings another side of the argument into the picture: how generative are the tokens? Stringing words together to make sensible sentences is easier than string letters together! A letter by itself doesn’t “mean” much, but a word carries a lot more information.
There is a spectrum between these options, and all LLMs today use a “subword” as a token with a process called byte pair encoding (BPE). For LLMs, BPE is learned from data: commonly used character sequences like “un-” or “pre-” will become tokens. Importantly, for LLMs, this type of encoding is easily learned from data. If you have an LLM-sized training corpus, you can just check what character sequences make sense as tokens over all of it.
BPE solves this by learning subword units. The algorithm is elegant: start with a character-level vocabulary, count all adjacent character pairs in the corpus, merge the most frequent pair into a new token, and repeat until reaching the target vocabulary size.
Before we move on, let’s summarize some of the tradeoffs tokenization induces, in a spectrum between fine (like letters) and coarse (like words) tokens:
Memory: Embedding table size better with fine tokens
Computation: Sequence length shorter with coarse tokens, but depends on algorithm
Generation: Easier with coarse tokens
Transfer: Words might be more task specific (e.g. a medical journal may have different types of words than a novel), but capture reusable task structure better (e.g. you can use an English to Italian dictionary to get by in Italy, vs. learning Italian from scratch from letters)
Execution latency and architecture flexibility: Fine tokens require very fast inference loops, but coarse tokens relax that and give more flexibility.
Action Tokens in Robotics
Robotics does physical work in the real world, and the most important part of that is the action. In this post, we will focus on action tokens instead of tokens for sensing or task input.
By analogy, a token is a small component of a larger task-directed behavior. If the task is to pick up a block, should a token be to move the joints by a few degrees, a Cartesian waypoint, or to complete the full grasp?
In a previous post, I wrote about two ends of this spectrum for exactly a task like this:

You can try the demo here too.
Basically all VLA models output fine-grained tokens, and the alternative approach used a VLM outputting coarse “move”, “grasp”, etc. commands.
Unlike the LLM “chatbot” interaction model where encoding and decoding are both part of standard usage, robot actions strictly only need to be decoded at inference time. If we are learning from imitation or demonstration, then an encoding step would be a part of training.
The tradeoffs from above can be ported over to make sense for robotics actions too, with some interesting implications:
Memory: This corresponds to the size of the “library” of action primitives that the robot is capable of executing. You don’t need to really store anything if the primitives are small joint motions, but memory demand could balloon if the primitives are more complex. For example, a robot arm may have hundreds or thousands of preset configurations, reaching motions, etc.
Computation: As exemplified by the robotics pipeline demo above, the Gemini ER model has a computationally simpler problem producing sequences of commands.
Generation: Easier with coarse tokens, as above
Transfer: Motion primitives might be more task specific (e.g. a pick-and-place vocabulary would not have “catch” and “toss” actions for juggling), but capture reusable task structure better (e.g. the primitives in the demo above are useful in for package logistics as well as loading a dishwasher)
Execution latency and architecture flexibility: The coarse tokens in the demo allowed us to combine hierarchically with model-based planners, whereas the VLA needs to run end-to-end
Behavioral Primitives in Robotics and Biology
Coarse action tokens are sometimes referred to as behavioral primitives.
The parallel to language (building up sentences from subwords and words) has been quite literally expressed in some robotics research (as a disclaimer, I was a Ph.D. student in the same lab):

In robotic behavior cloning, object-level and action-level abstractions can be learned from training data (the BPE equivalent):

This paper shows the emergence of synergies from reinforcement learning of humanoid locomotion.
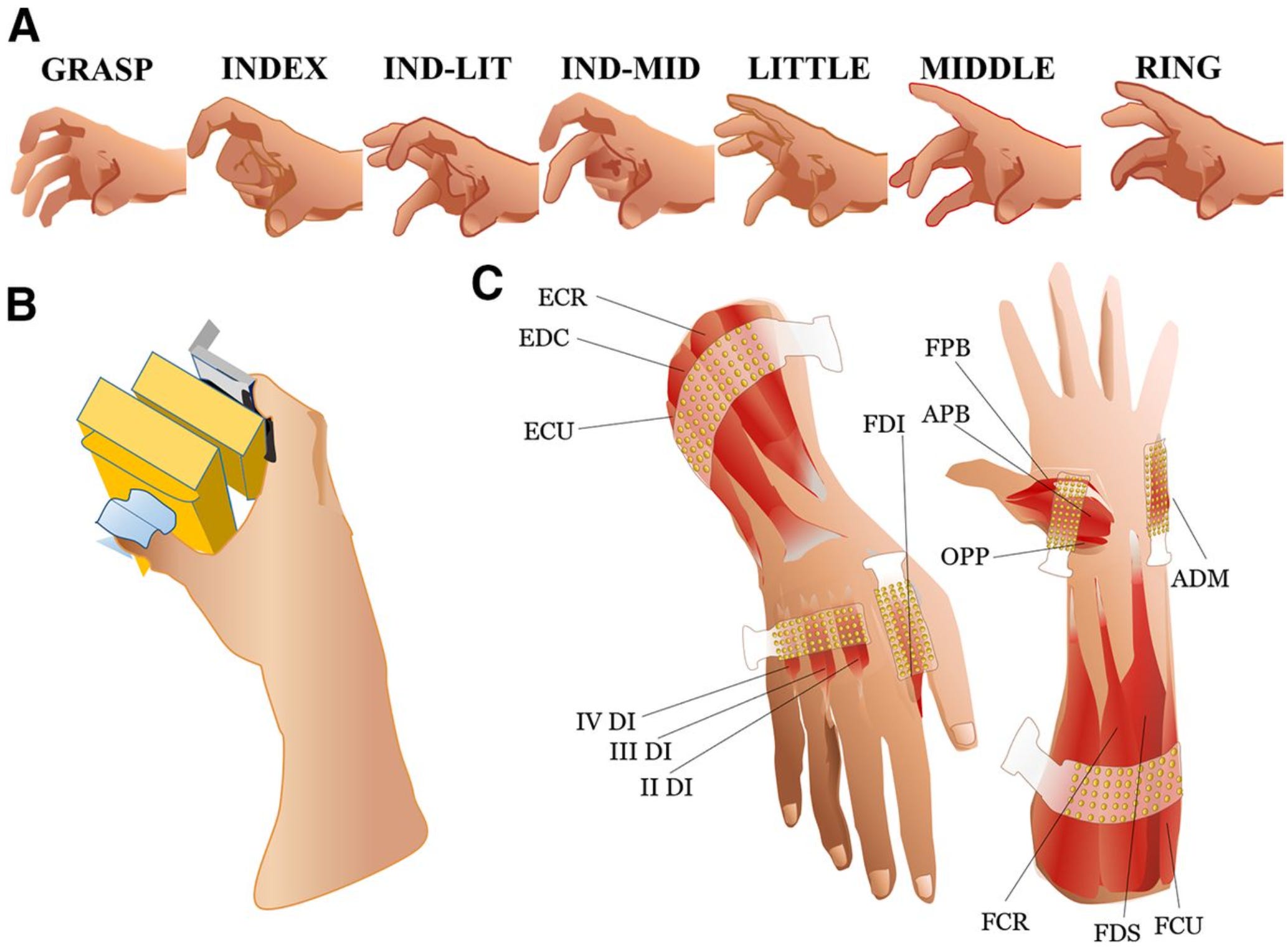
In biology, motor synergies coordinated in the spinal cord allow multiple joints to be coordinated to produce coarse tokens:
The resulting behavioral primitives can be recognizable subcomponents of tasks:
Closing Thoughts
A token in an LLM or a robot can be either very fine-grained or coarse. Due to the rich tradeoff space, there isn’t an absolute correct answer for what to choose, and the best decision may change over time and for different applications (as Anthropic found with Opus 4.7).
Not enough attention has been paid yet to the implications of this choice for robotics. In addition to the technical tradeoffs I discussed above, it can have some very important downstream effects on the ecosystem of research: fine-grained tokens make the robotic stack monolithic, while coarse ones allow for parallel progress in low-level control and higher-level cognition that can be vertically integrated for a particular application. This also has an impact on how the research ecosystem can be structured.
The course of world model research and continued robotic deployments in 2026 may shed some more light on the best choice for different applications. I’ll look forward to covering major developments in this area in future posts. Also, stay tuned for a follow-up on the parallel to instructions in computing and the RISC vs. CISC debate.
Thanks for reading!
If you enjoyed this post, please like (❤️) and restack — it helps others find my writing. Subscribe to receive new posts. All of this is greatly appreciated.