
Building a reasoning hierarchical robotics pipeline from scratch
Part 5: A demo combining the best features of end-to-end and classical approaches

End-to-end Vision-Language-Action (VLA) models bundle perception, reasoning, and motor control into a single network, but that means the camera, kinematics, and training scenarios are all baked in together. This could cause unexpected and unresolvable issues when the task, embodiment, or environment change.
To showcase and demonstrate some of the insights from the past articles, I’ve put together a demonstration of the insights from this article series that you can try out, modify, and learn from. This demo combines the flexible task programming and reasoning of the Gemini ER Vision-Language-Model (what is the scene, and what should I do?) and classical camera calibration, kinematics, motion controllers.
This post describes how it is put together, goes over of some of its interesting capabilities, and the aspects of its design that directly impact its strengths and weaknesses. To conclude, we will try to compare this approach against fully modular (model-based) as well as fully end-to-end methods. The code is open source, and I’m putting the ideas out there for discussion and feedback.
This article is the last part of a series on end-to-end robotics pipelines. Links to the other articles are below.
Trying out the demo
To make it as accessible as possible, the demo runs in the browser with no software installation required, and can be accessed from your computer or even a phone. Click this button or to open the page:
The environment is set up for tabletop manipulation with a robot arm. The colored blocks are objects that we can instruct the arm to move, the “plates” can serve as potential goal locations, and the grey cylinders can serve as obstacles to be avoided.

The demo uses a Gemini Robotics ER model for task reasoning and perception. To try it out, you need to grab your own Gemini API key (free tier), or use the pre-baked fallback plan, which will execute the “Put the blocks away where they belong” default task. Correspondingly, click “Run Task” (with API key) or “Use Cached Task” and watch! Use the mouse to orbit the camera, and check the console for debug logs.
What it does well
Flexible task programming and reasoning. Tasks can be prompted without needing task-specific programming, which is a major selling-point: the possible tasks are not limited by what is programmed at the factory. Gemini processes the prompt together with the scene and can break down multi-step tasks. We’ll go over how Gemini’s outputs are used by the rest of the system below.
Results from some tasks:
Place the red block on the blue target
This simple task shows the VLM’s visual and task understanding. Additionally, its language understanding can parse semantically similar words in the context of the scene (e.g. block vs. cube, or plate vs. coaster vs. target).
The video also shows the reactive obstacle avoidance allowing the arm to not collide with the cylindrical obstacles. This capability, with associated safety benefits, does not require any training or motion primitives to be built into the VLM. More on that below.
“Put the blocks on matching targets”
The VLM successfully reasons that blocks go on color-matched plates, and breaks down the task into a number of steps (move red block, move blue block).
“Swap the red and blue blocks”
This task requires a multi-step plan to move one of the blocks out of the way first, and the selection of a free location to store it.
The wireframes displayed in the animation show the spatial understanding ability built from a combination of a Gemini VLM with classical computer vision. Objects in the scene are semantically classified — into objects (blue wireframes), potential goal locations (green), and potential obstacles (black) — by the VLM guided by prompting, without hardcoding.
As a note of caution, I had a few runs where it chose the “free” location incorrectly on top of another block.
“Put away the blocks”
The success of this (underspecified) prompt showcases the language and intent understanding of the VLM. However, I will temper with the note that in some runs, it did try to move the green block and confuse itself — feel free to try it yourself!
“Wave”
This silly task shows that the VLM’s task understanding goes beyond tabletop manipulation, as it can produce waypoints just intended for arbitrary motion. However, this demo will only successfully perform horizontal motion due to the 2-dimensional understanding of the VLM — more on that below.
What is challenging
The principal weaknesses are also to do with the 2-dimensional understanding of the VLM.
“Stack the blocks”
It correctly moves multiple blocks to the same horizontal position, but does not properly reason about the vertical location of each drop-off. This results in the later blocks getting smashed into the ones already placed.
The architecture explains strengths and weaknesses
The architecture of the demo is shown below:
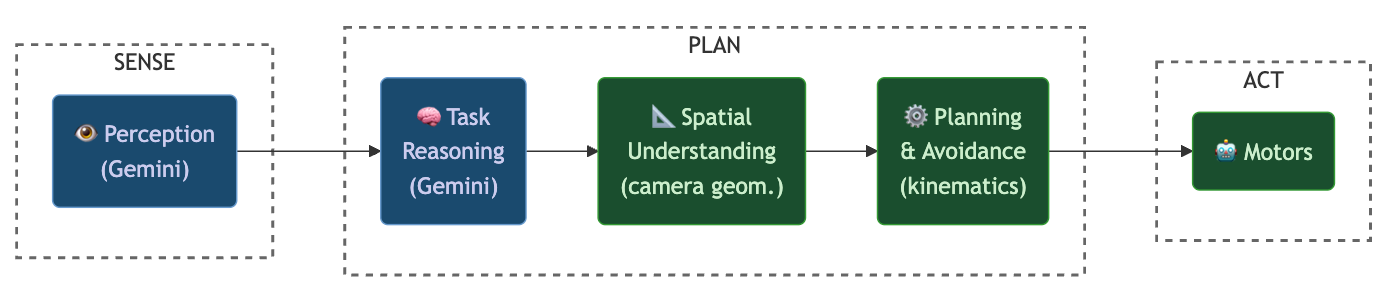
Gemini (VLM) blocks are blue, and blocks built using classical methods are green. Each layer is independently swappable, and the AI model doesn’t need to know anything about the robot’s embodiment. This recreates the modularity of a Sense-Plan-Act architecture while retaining the semantic reasoning of a foundation AI model.
Vision-Language Model (VLM)
The demo uses Gemini ER, whose inclusion I previously motivated with a coding agent analogy. Its inputs are the text prompt and a single image, and its outputs are grounded in pixels in the same image. This keeps its behavior well-defined and decoupled from the robot embodiment, solving many of the issues with X-VLA in a similar setup.
However, it builds in a few assumptions that should be acknowledged. Most importantly, its understanding of the world is decidedly planar (pixels in the image plane).1 The view must therefore be chosen to avoid occlusion, parallax-related issues as the camera moves, and tasks that require positioning along the camera axis (like the block-stacking task above).
Gemini ER can be prompted to output structured JSON, which is easy to work with in downstream layers. The system is first prompted for “perception”, which does object detection, semantic classification, and bounding box identification. All of these are very common functions, and easy for this model to complete in ~1 second. An example output for the perception block is below:
[
{
"label":"green block", // <- a name
"point":[637, 232], // <- position in image coordinates
"box_2d":[531, 157, 743, 305], // <- image coordinates of bounding box
"type":"block" // <- semantic classification
}, // ... other detections
]The next step asks the model to plan the motion for a task. We specify an output format that limits the output to “calling functions” that the arm and its lower-level controller is capable of executing. Example output from Gemini (took anywhere from 4-10 seconds):
[
{
"function":"move", // a function that moves the arm
"args":[584, 753, false], // position (image coords) + 1 bit indicating height
},
{
"function":"setGripperState", // a function that closes or opens the gripper
"args":[false] // false to close, true to open
}, // ... other steps
]The full prompts to get these outputs are part of the open-source package.
Spatial understanding
First, we convert the image-plane understanding of the VLM into spatially accurate waypoints that the arm can act on. For this conversion, I also sampled depth values from the camera location (easily reproducible with stereoscopy or a model like DepthAnything). I chose to use the bounding boxes to isolate the depth values in a region around the object center, and use that to fit primitive shapes to the detections (rendered with wireframes in the videos above). This can be done by well-understood camera geometry transformations, and also allows for relocation of the camera, unlike in a VLA where the camera geometry is inextricably linked into the rest of the model. The output of this block is 3D waypoints and a representation of the obstacles.
The object shape affects how well a bounding box captures inlying depth pixels. Gemini also has a native ability to output segmentation masks, which could allow for further refinement in this computational block.
Model-based local planner
The next part is a model-based local planner that actually generates control signals. This decouples the control rate from the slow runtime of the VLM completely, and no retraining is needed to generate novel motions for new scene compositions. Adaptations for payload could be built into this layer without affecting VLM.
For obstacle avoidance, we use a “potential field” that pushes the end-effector away from obstacles (you can see orange arrows appearing briefly in the animations above), while moving toward the desired goal. This is a classic reactive motion planning technique, one of a family of well-understood algorithms along with sampling-based and grid-search planners.
The interface is crucial
The VLA approach had no choices to be made about the type of interface — when trained on the same embodiment end-to-end, input pixels get mapped straight through to actions. However, with this hierarchical controller, the choice of interface is quite important. While it resolved many of the drawbacks of the full end-to-end approach that held back a demonstration like this, one of the interpretations of the bitter lesson is that any hand-crafted interface design hampers system performance.
For example, for grasp generation in this demo, we have to assume that knowing the location of block is sufficient to produce an action to grasp it. However, different grasping actions may be needed for soft or unusually-shaped objects, like eggs, cloth, etc. One possible extension to resolve this is to incorporate a grasp generation module seeded by the object centers and bounding boxes. A VLA will just directly output actions, which is not limited by this kind of architectural judgment, but also may require a lot more training data and fail unpredictably when out of distribution.
Scoring the criteria from the first article
The architecture described above is neither an end-to-end VLA, nor a modular model-based one. For specificity in this section, I’ll assume the former camp as being represented by something like Physical Intelligence’s models (a small version of which we tried hands-on with X-VLA), and the latter as being represented by the MIT 2014 Atlas method. Both were discussed in the first part in this series about end-to-end robotics pipelines.
All that said, where does this “hybrid” hierarchical strategy fall? We identified a number of criteria in previous articles, and can try to roughly size up where each falls:
My summary would be that the end-to-end method can be the best if it is scaled potentially ad infinitum and has very fast computational hardware, which has practical (data requirements) and efficiency drawbacks. I think the hybrid architecture could be a good middle ground to greatly expand capabilities with less data and added safety and efficiency, but has some bottlenecks from interface choices that may impact some applications (but in a predictable way). I’m open to your thoughts — let me know below!
Closing thoughts
This demo was put together with models released within the last year, but also with ideas that have existed for decades. We’ve been seeing transformational improvement in the capabilities of deep neural networks, leading in many cases to large strategic shifts to embrace fully end-to-end architectures. However, this shift brings with it new problems in safety, efficiency, and predictability. This post goes over a proposal for a hybrid architecture that attempts to draw on the strengths of both camps.
There is room for improvement in end-to-end VLA approaches with scaling, as well as in this kind of hybrid architecture (faster VLM inference, multi-view VLM). “World model” methods are rapidly gaining popularity as a component of larger modular pipelines (stay tuned for future posts on this topic). I also plan to look more into how to build an “embodied reasoning” open-weight VLM in future posts.
Please check out the demo, and the source code.
If you liked this post, please like ♡, share, restack, and subscribe — it helps others find my writing.
Further reading
Other articles in this series:




I wonder if a VLM could be built with stereoscopic vision and some way to associate objects in the two images. Let me know in the comments if you know of anything like this!
Nice balance here between modern VLM reasoning and classic robotics control, especially for handling real world edge cases