
Debugging as architecture insight: dissecting a VLA
Part 3: Hands-on debugging of a vision-language-action model as a lens into architecture, safety, and verifiability

This article is part of a series on end-to-end robotics pipelines. I’d recommend at least reading part 1 after this article.
In this part, we get hands-on and build a VLA pipeline from scratch. I’ll be transparent about my starting point: while I have experience with model-based methods, RL controllers, and LLMs/VLMs, generalist end-to-end policies — almost exclusively being realized today as Vision-Language-Action (VLA) models — were new territory. That makes this post a useful vantage point to evaluate their strengths and weaknesses from first principles, and should be interesting to those who have never heard of VLAs as well as those who use them daily.
“Pick up the red block”
The demo is simple: take a specified prompt (like the one in the heading above), run it through the model, and visualize the actions that the model outputs. Obviously, when it is run in closed loop, you would get motion that hopefully results in the action described by the prompt, but there was so much to dig into with just this visualization that it made sense to spend an article on it. In the next part, we will close the action loop and explore some of the low-level controller facets mentioned in part 1.
In the following animation, the configuration of the arm is changed using the sliders (while being given the same prompt), showing that the output action is responsive to the robot and environment state.
The learning journey for this article is captured in a Jupyter notebook that can be accessed and run for free on colab — click here. All details on the software stack are in the open-source github repository for this project (which is where the notebook file also is). If it is a helpful learning tool or template, I’d welcome any feedback, fixes, contributions, stars, forks, etc.
First, let’s quickly go over what a VLA is.
Anatomy of a Vision-Language-Action (VLA) model
A Vision-Language-Action model has three functional components: a vision encoder, a language encoder, and an action head. In practice, the vision and language encoders are almost always a single pretrained VLM, i.e. the vision and language processing are already jointly trained before the action head is added. This means the “vision encoder” and “language encoder” aren’t independently tunable modules; they’re entangled by pretraining.
The architecturally interesting variation is in how the action head attaches to the VLM, and how much of the VLM is modified during robot training. This single design choice has large downstream consequences for what you can and cannot inspect at inference time.
VLA “action head” architectures
Two illuminating (but not exhaustive) designs:
Octo uses a dedicated readout token — a learned embedding (~384-dim) that aggregates action-relevant information from the transformer before a small decode network produces actions. This bottleneck is the closest thing to an inspectable interface in any current VLA: you can probe whether the readout encodes directional intent, object identity, or nothing interpretable.
Transformer → readout_action embedding (384-dim)
↓
Action Head (direct decode)
↓
ActionsX-VLA processes images, language, proprioception, and noisy action candidates together in a single 24-layer transformer, conditioned by 32 learnable soft prompt tokens selected per embodiment. Flow matching then iteratively refines the action chunk over 10 steps. Action-relevant information is distributed across all layers and token types simultaneously.
Input: Images + Language + Proprio + Domain ID
↓
┌───────────────────────────────────────────┐
│ Soft Prompt Selection (per embodiment) │
│ Domain 0 → Prompt_0 (32 learnable tokens)│
│ Domain 1 → Prompt_1 (32 learnable tokens)│
│ Domain N → Prompt_N (32 learnable tokens)│
└──────────────┬────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ Unified Transformer Stack (24 layers) │
│ ┌────────────────────────────────────┐ │
│ │ [Soft Prompt | Vision | Lang | │ │
│ │ Proprio | Noisy Actions] │ │
│ │ │ │
│ │ All processed together with │ │
│ │ standard self-attention │ │
│ └────────────┬───────────────────────┘ │
└───────────────┼──────────────────────────┘
↓
Flow Matching (10 steps)
↓
Action Chunk (32 actions)The soft prompts enable efficient cross-embodiment adaptation: only ~9M parameters (1% of the model) need updating for a new robot. But they also mean embodiment-specific behavior is encoded in vectors with no interpretable structure.
The deeper point applies to both architectures: even where a vector interface exists between components (Octo’s readout token, X-VLA’s soft prompts), end-to-end training means those vectors don’t have a physical interpretation that safety constraints can be applied to.
There is more to be said on action chunking and control bandwidth, which I’ll plan to do in the next part of the series.
Model choice
I approached this as a user rather than a researcher: published weights only, no training data collection, and no fine-tuning iterations before deployment. The target application is tabletop pick-and-place on a WidowX, which is a common manipulation benchmark and exposes the control and perception properties I care about. Another soft constraint was that I’d be able to run it on my personal laptop (12GB VRAM).
These three criteria limit which VLAs can be tried. OpenVLA-7B requires task-specific fine-tuning and won’t fit in 12GB without quantization. π0 needs 24GB+. GR00T requires a Jetson Thor. Gemini Robotics On-Device is trained on dual-arm configurations and isn’t publicly accessible. Octo (93M params) fits the hardware but its pretraining doesn’t support zero-shot transfer without fine-tuning. SmolVLA likewise requires fine-tuning.
X-VLA seems to fit the bill. Its soft-prompt architecture was designed for cross-embodiment zero-shot transfer, and xvla-widowx provides a checkpoint fine-tuned on BridgeData for the WidowX embodiment specifically, meaning embodiment adaptation is handled, while task generalization remains zero-shot. It also has a ee6d (end-effector coordinates) action output mode, which appealed to me because it would allow elimination of kinematics-related variability.
What’s different about VLAs: task programming
VLAs have been heralded as revolutionary for robotics, and it’s true: the prospect of robot programming with natural language is a decided shift. Thinking about my own fielded robotics experience at Ghost Robotics, either customers would (a) directly command the robot, (b) pick between preprogrammed tasks (which can be considered a fixed small vocabulary of commands), or the robot would start its own tasks. Giving natural language commands increases the set of tasks without retraining or reprogramming. The natural language interface changes who can program a robot, not just what it can do. With a VLA, a non-technical operator can in principle specify novel tasks.
The flip side worth mentioning fairly: natural language as an interface trades a small precise vocabulary (preprogrammed tasks) for a large ambiguous one. “Pick up the red block” sounds more expressive than running the “pick_red” preprogrammed task, but as the next section will show, the boundary of what the model actually understands is opaque in a way that a fixed command vocabulary is not.
What’s different about VLAs: calibration and debugging
With classical methods, the process of setting up and debugging a task includes several well-delineated steps:
calibrate cameras → check camera detection overlay → perception ✅
calibrate joints → send arm “move up” command and ensure it moves as expected → actuators ✅
With VLAs, there are a few reasons why this kind of unit testing or debugging is simply not possible.
Camera extrinsics or joint torque constant parameters will not be isolated: datasets are typically trained with multiple camera angles without explicit calibration, and network learns spatial transforms end-to-end.1 Another example: swapping the camera lens for a fisheye for a wider FOV won’t generalize without retraining, unlike traditional vision where you just recalibrate intrinsics.
There aren’t obvious equivalents of non-end-to-end interfaces such as the camera detection overlay or a “move up” command, but we will try to come up with methods to work around this in the next section.
Randomness: the trajectory will vary with no environmental change. Flow matching stochasticity is in the action head specifically; the VLM backbone is deterministic given the same input. X-VLA uses 10-step flow matching. Even with same seed, numerical precision in GPU ops causes drift by step 5-6
Due to a combination of 1 and 2 (and slightly exacerbated by 3), it can be complex to reason about the root cause of a failure. Is failure due to (a) vision error, (b) action discretization error, (c) world model mismatch, or (d) all three? When can you dismiss a failure as being out of distribution vs. not?
For a developer, this ambiguity is an inconvenience; with enough time, you can run more experiments and form hypotheses (as we do in the next section). For a deployed system in customer hands, the same ambiguity becomes a safety property: the robot has no reliable mechanism to detect that it is out of distribution and should stop. Classical systems fail loudly (joint limit hit, object not detected, planner infeasible); VLAs fail silently, producing plausible-looking but wrong trajectories. This isn’t a criticism of VLAs specifically, but it is a structural consequence of end-to-end training, and it applies equally to any system where the failure boundary is defined implicitly by a training distribution rather than explicitly by an engineer.
VLA debugging ideas and techniques
Despite the structural challenges mentioned above, I had a fascinating experience coming up with ways to probe and understand what the VLA was doing.
Passive debugging: inspect what the model is already computing
Interpret VLM output (infeasible). My first instinct was to query the VLM backbone directly, e.g. by asking something like “Is there a red cube?” or “What objects are on the table?” to verify perception. This turns out not to be feasible for most architectures. In X-VLA and SmolVLA, the action head attaches to the VLM’s final hidden states and generates actions through flow matching in a continuous space, bypassing the text vocabulary entirely. You could query the underlying base VLM (e.g. SmolVLM2 for SmolVLA) separately, but that’s not a fair proxy: fine-tuning on robot manipulation data shifts the VLM’s internal representations, so its text generation behavior no longer reflects what the VLA backbone actually sees. This technique only works cleanly in text-token VLAs like VLA-0-Smol, where actions are generated as autoregressive text strings from the same output head as language. There, scene description quality and action quality share a representation and if the model produces a poor scene description, it will likely produce poor action tokens.
Visualize attention on tokens. The ubiquity of transformer-based architectures means that we can leverage the HuggingFace transformer’s output_attentions feature to try to visualize where the vision and text encoders are spending their attention, and if it is appropriate for the task specified. E.g. if we ask it to pick up a red block, is the vision encoder indeed looking at the red block?
Active debugging: intervene on inputs and observe behavioral change
Camera ablations (test whether vision is doing object detection or spatial template matching). Move the camera position, and introduce occlusions into one of the views if there are multiple. If attentions fail to track the desired object, it suggests the model learned spatial heuristics tied to camera geometry rather than object identity. In a classical pipeline, object detection is camera-pose-invariant by design (you’d re-project into robot frame), but here, camera pose is baked into the learned policy implicitly through the training distribution.
Counterfactual prompting to test semantic understanding. Use variations of the prompt (e.g. red block vs. red cube) that effectively mean the same thing and observe if the output stays consistent. Different outputs exposes that the action head is sensitive to tokenization differences that the VLM alone would smooth over. Also,
Primitive action prompts (tests action head’s semantic understanding of motion). E.g. if “don’t move” produces as much motion as “pick up block”, it shows that the action head is always generating motion from its training distribution, v.s. containing a deeper understanding of what motion is.
I suspect that some (if not all) of these will be familiar to seasoned VLA users, but please let me know in the comments if you’re aware of a better technique — chances are that it will many prospective and current VLA users!
Debugging results
For each experiment, I’ll write what a reasonable expectation would be, the result we see, and the resulting insight or the deeper reason why.
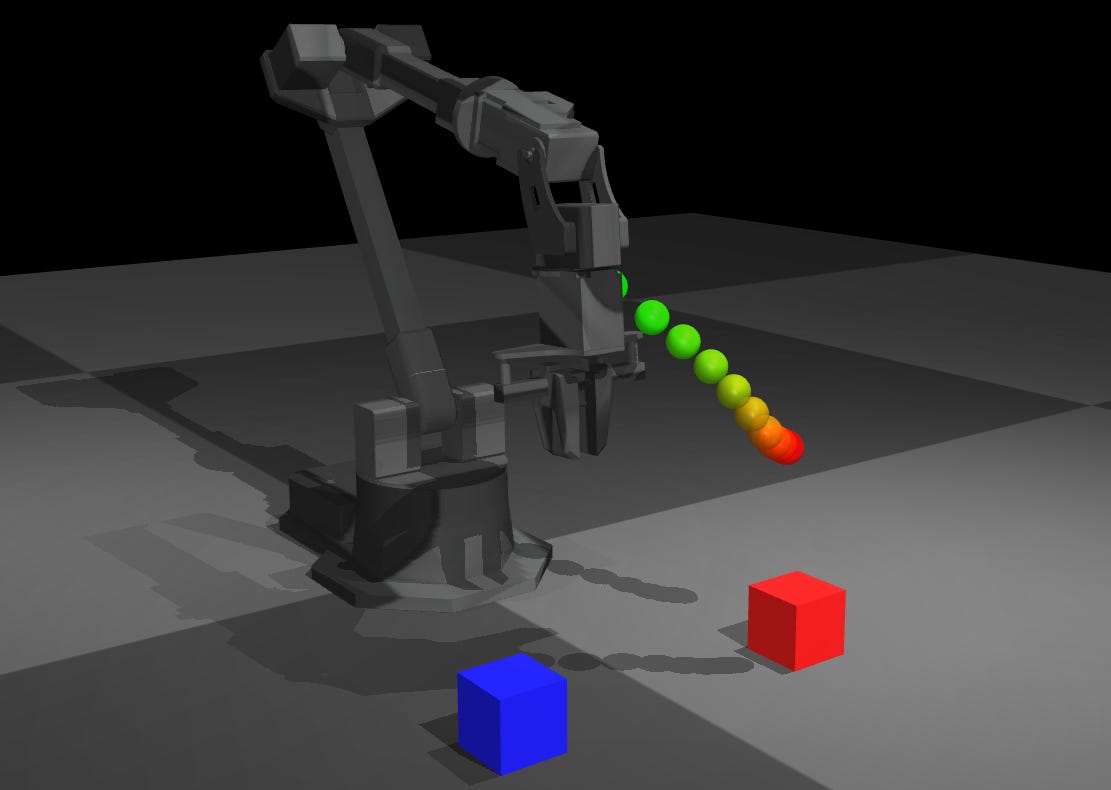
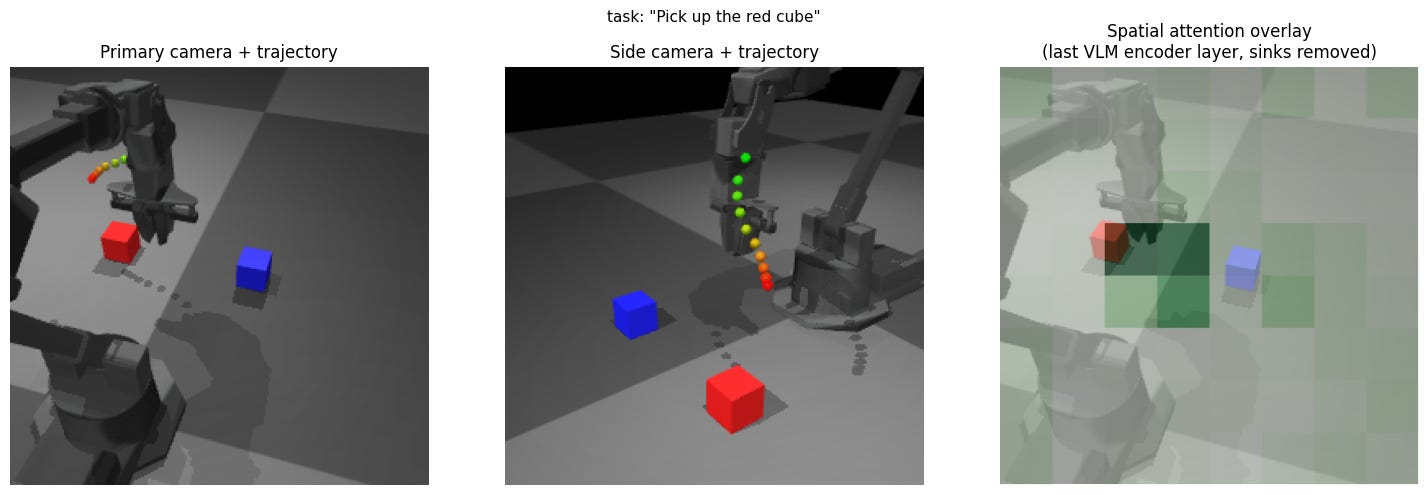
Baseline: pick up the red block
In this baseline, the attention mask on the image looks like it is looking at the red block as well as the gripper. The reaching trajectory output looks like it moves to directly over the red block. Overall, this looks to be a great initial result.

Experiment 1: Picking a different block in view
Expectation: Symmetric action based on spatial understanding from multiple views
Result: The visualized attention shows that it is looking at approximately the correct part of the primary image, though it appears a little offset to the outside of the block. The reaching action appears to not reach as far toward the blue block.
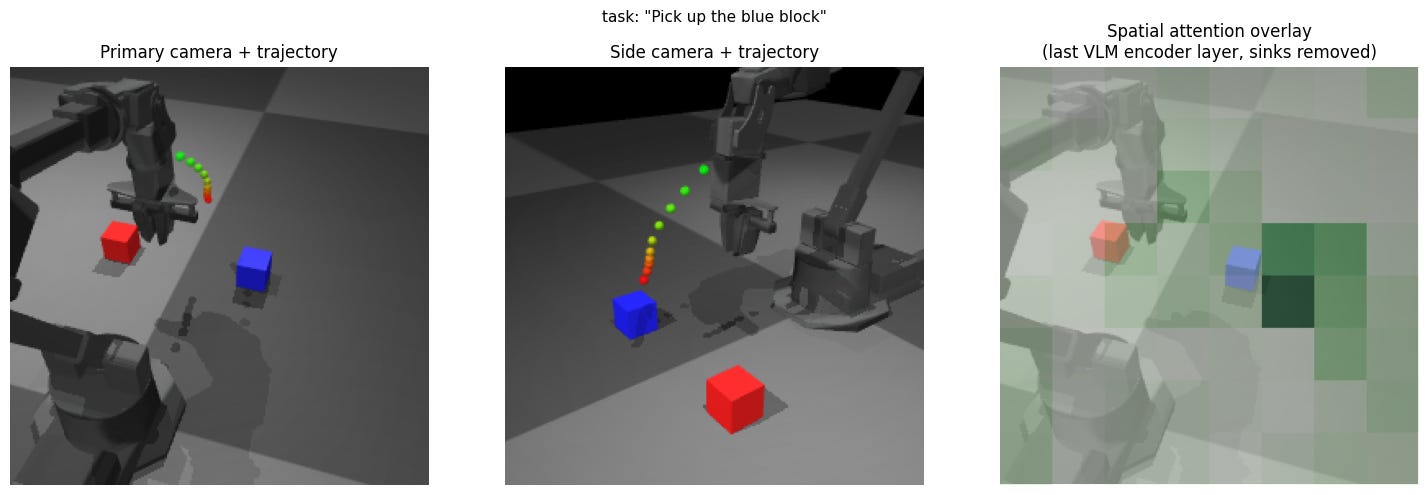
Insight: Most likely, the “3D” spatial understanding from the images is not exactly what we would expect from an exactly calibrated perception and object identification setup.
Experiment 2: Swap blue / red positions
Expectation: Symmetric behavior from previous experiment.
Result: Blue trajectory overshoots more compared to initial red block trajectory, and red trajectory overshoots.
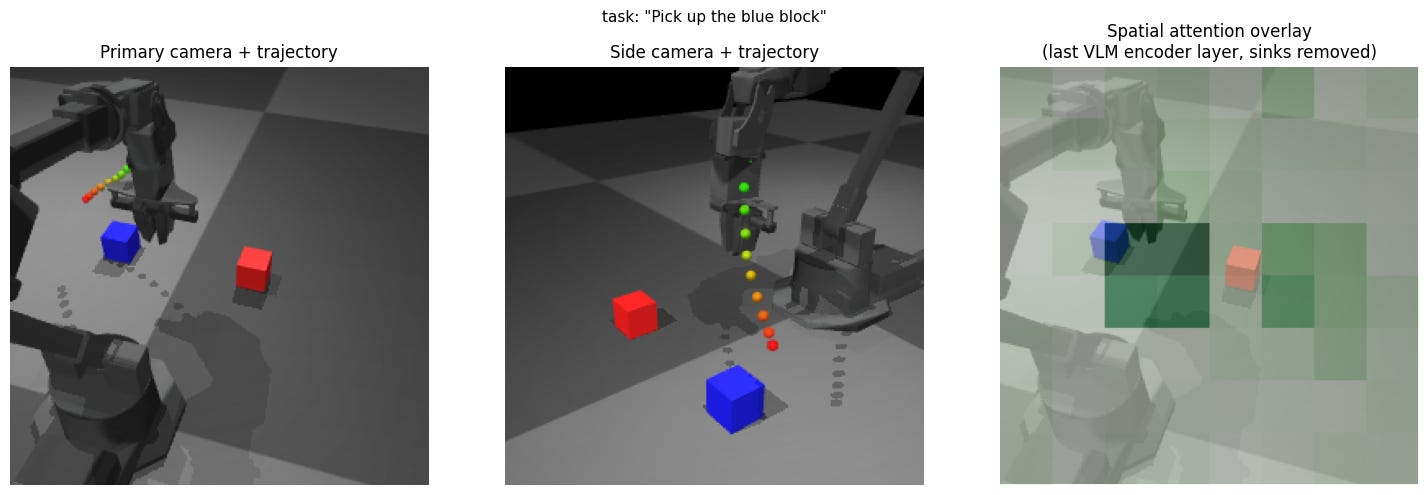
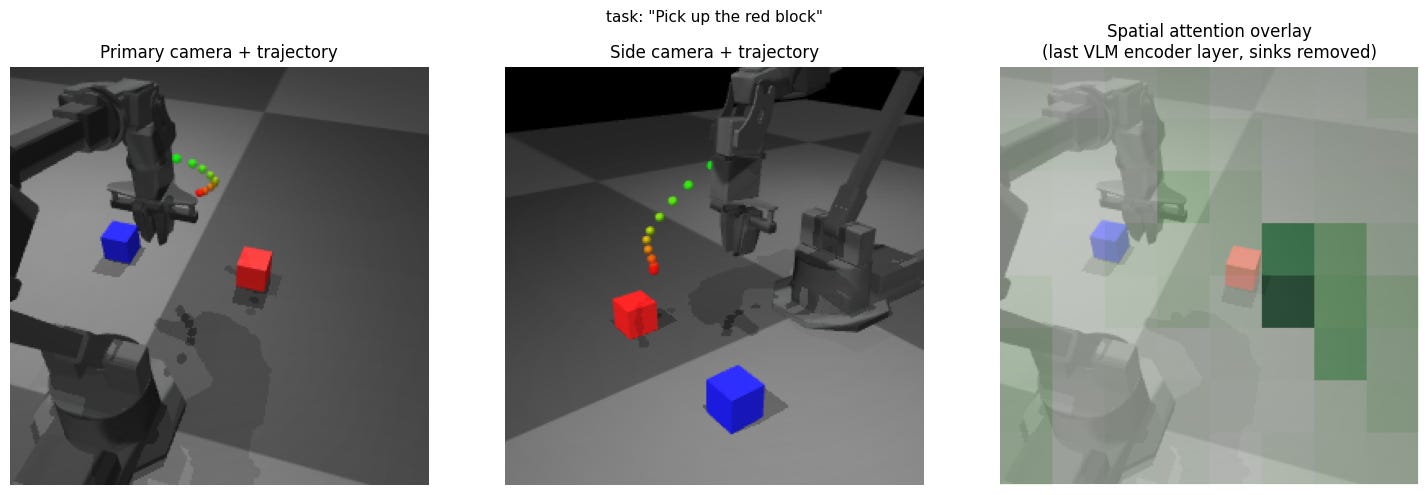
Insight: Spatial understanding and behavior is not symmetric when it is expected to be, indicating a bigger effect of things like training data distribution.
Experiment 3: Altered primary camera view
Expectation: Same behavior as the initial camera view.
Result: The red block trajectory now exhibits the under-reaching from the blue trajectory before, and vice versa.

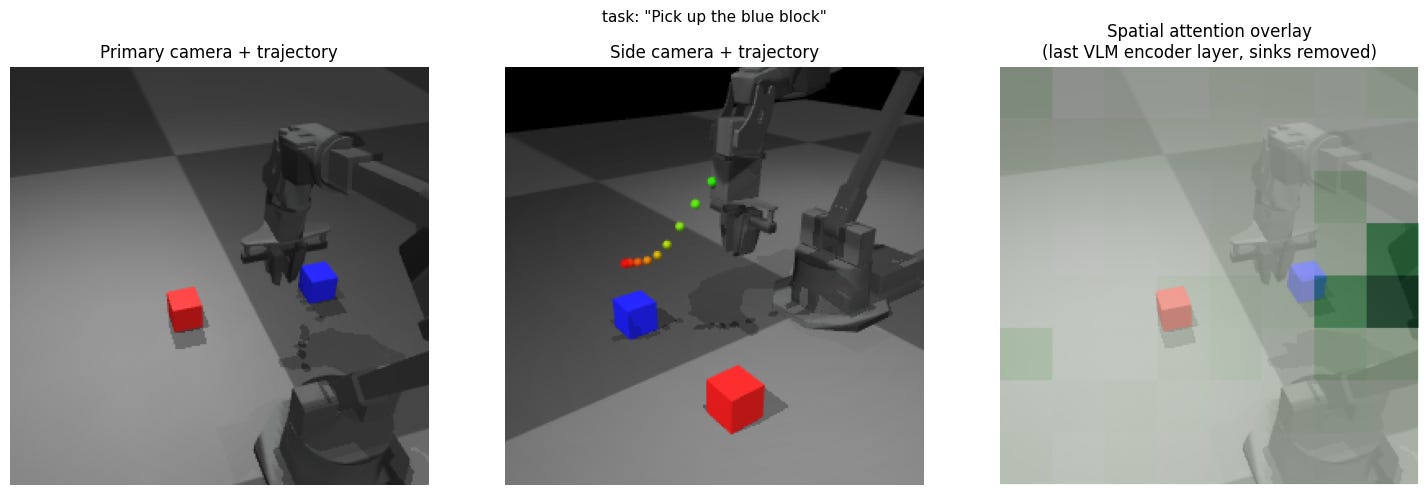
Insight: The actions are inseparably tied to the camera view and not associated with absolute spatial understanding.
Experiment 4: Remove second camera view
Expectation: Slight degradation in performance.
Result: Removing the side view has minimal effect, but removing the over-the-shoulder view has a disastrous effect on performance.

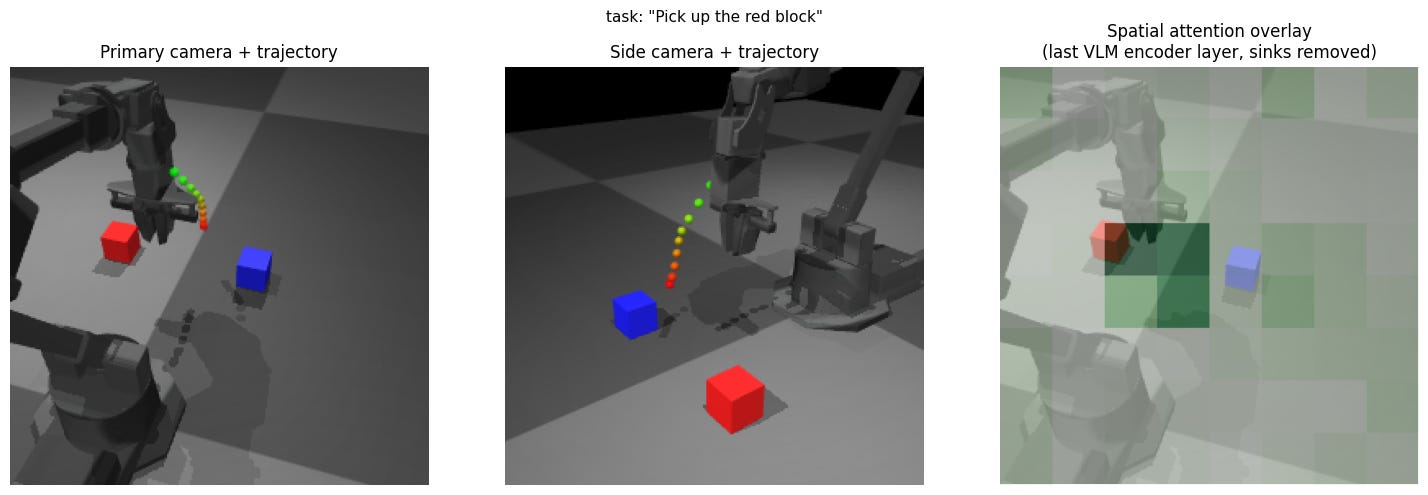
Insight: It appears that BridgeData has a disproportionately high number of trials with the over-the-shoulder view and significantly altered view points may silently produce much worse results.
Experiment 5: Occluded primary view
Expectation: Second view provides redundancy.
Result: Trajectory moves away from the red block.
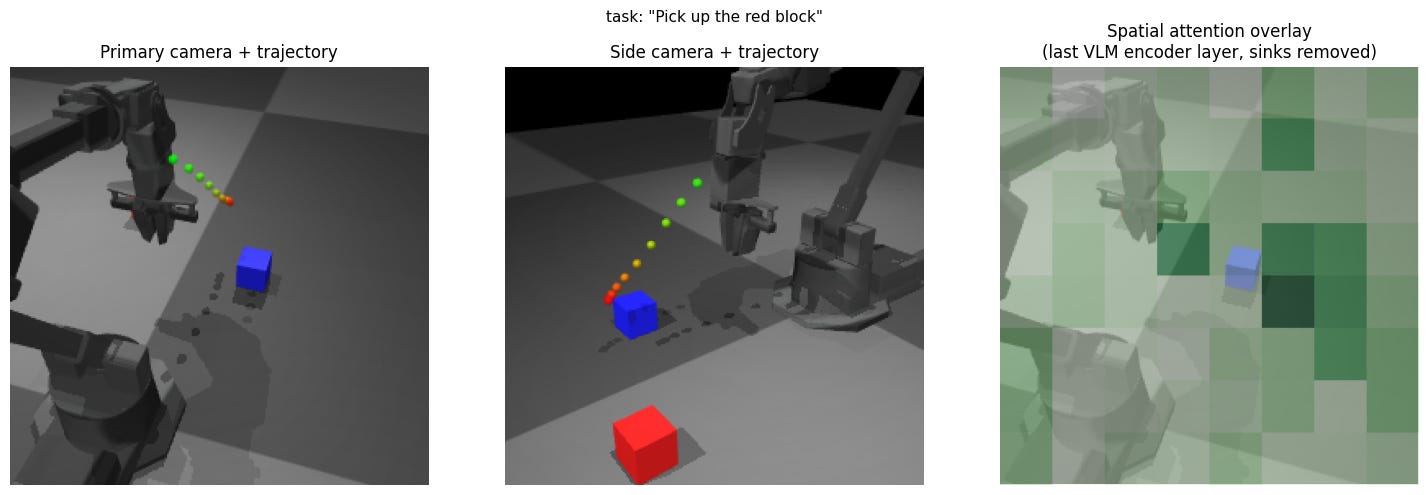
Insight: The side camera view seems to not be useful in X-VLA.
Experiment 6: Prompt variations
Expectation: Similar-meaning prompts will produce similar actions.
Result: All these similar prompts largely resulted in similar actions.



Insight: The language encoder is effective at collapsing equivalent prompts to the same actions.
Experiment 7: Don’t move
Expectation: No motion.
Result: Approximately as much motion as when asked to pick the red cube with the left shoulder view.

Insight: the model is still interpolating / extrapolating from training samples and does not have an explicit understanding of commands.
Experiment 8: Change picking position
Expectation: The output trajectory moves to the modified block position.
Result: The visual attention is strangely not on the block in the second example, but largely, the trajectory is responsive to the environment change.
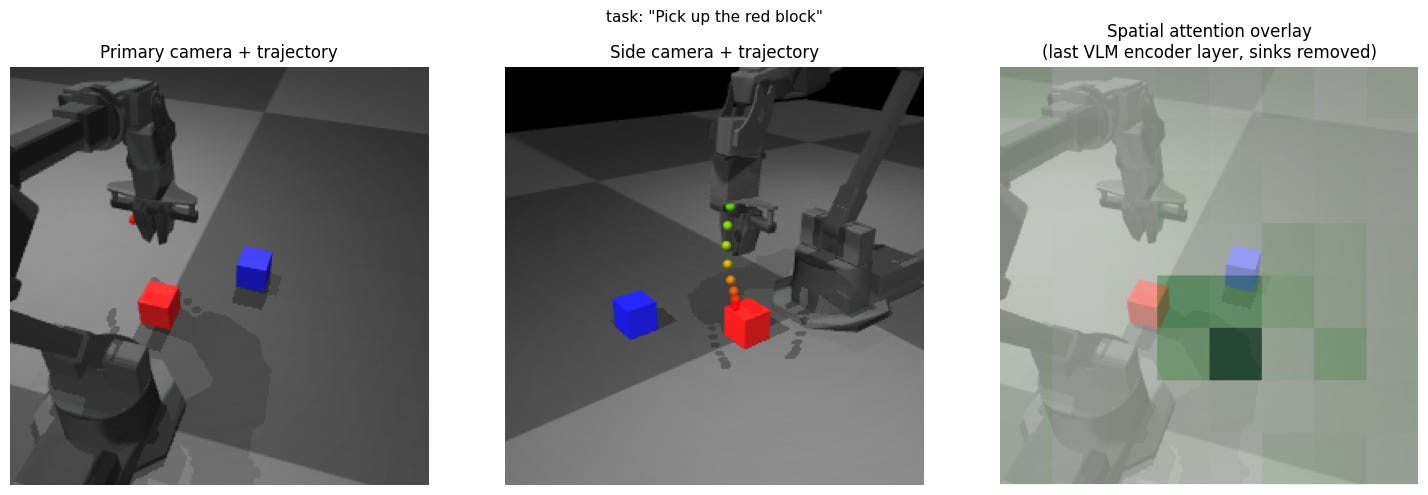

Insight: As long as the prompt is visually grounded, the results generalize in the expected way. Soft prompt for WidowX likely encodes “approach visible object” as primitive (trained on Bridge dataset).
Experiment 9: Move forward / backward / up / down
Expectation: Move as asked.
Result: Approximately the same motion toward the tabletop, largely uncorrelated with the prompt.
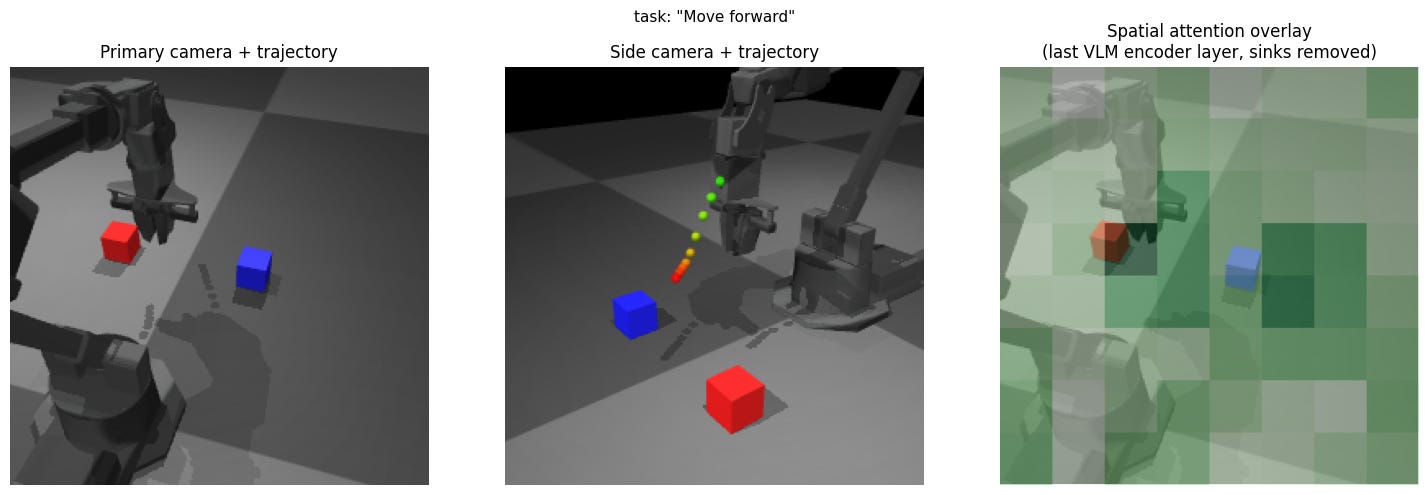
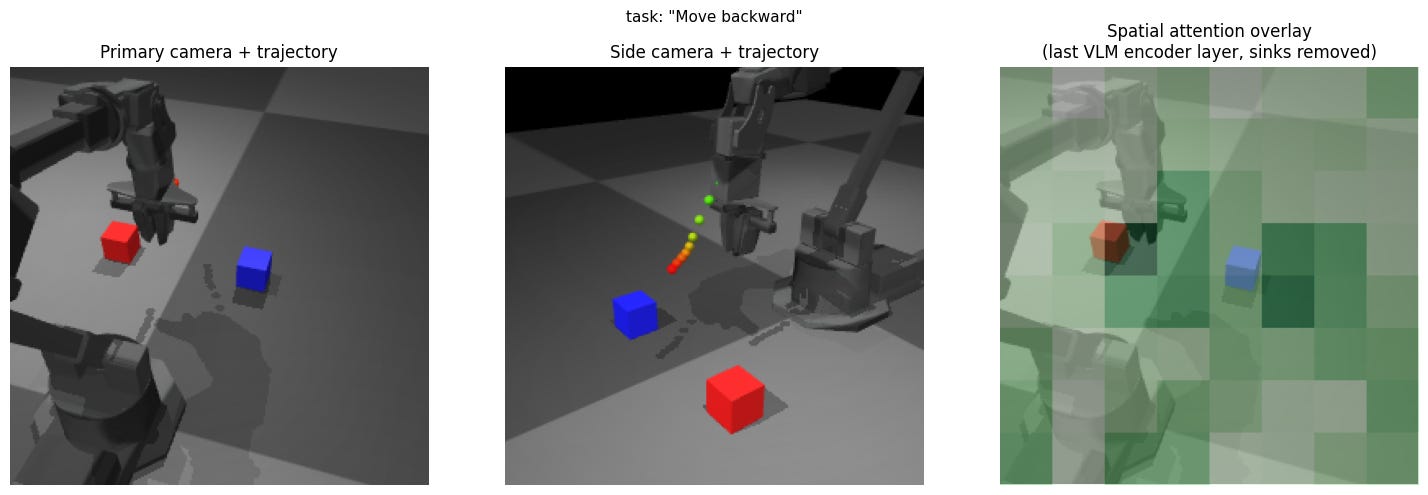
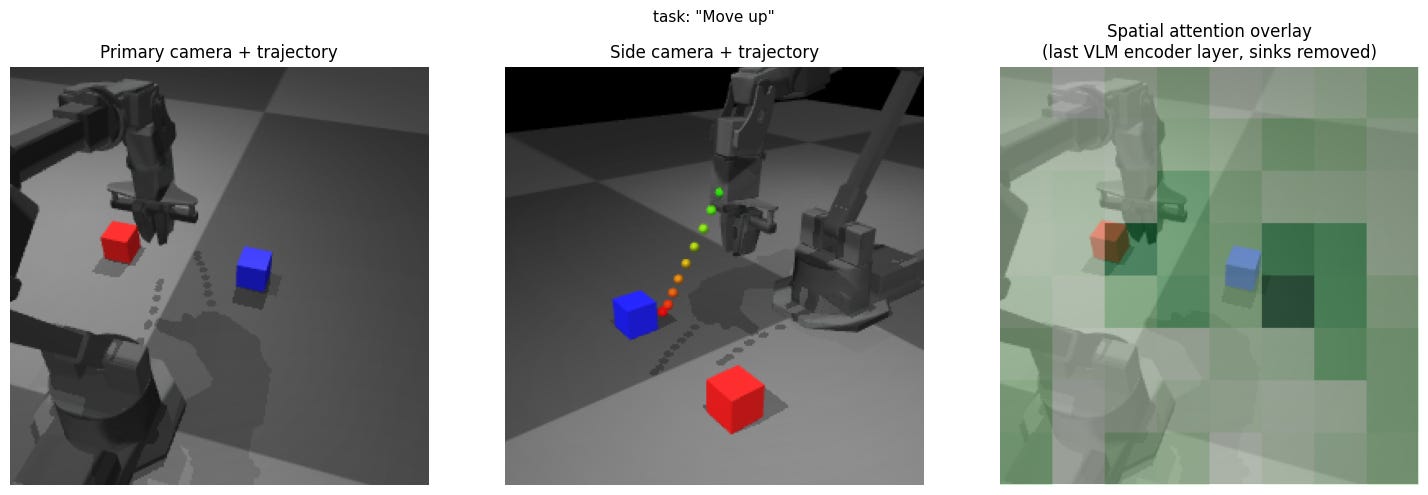
Insight: No visual grounding for blind motions. The model has no spatial primitive vocabulary because VLMs are trained on image-caption pairs where “up” describes scene composition, not robot workspace direction.
Experiment 10: Move toward / away from base
Expectation: Move as instructed.
Result: Discernible difference in the two trials accordingly, suggesting some comprehension of the prompt.


Insight: The introduction of the robot base as a (visible) target makes things significantly easier for the model compared to the previous experiment.
Experiment 11: Move away from block
Expectation: Motion away from the block.
Result: Motion largely toward the tabletop.
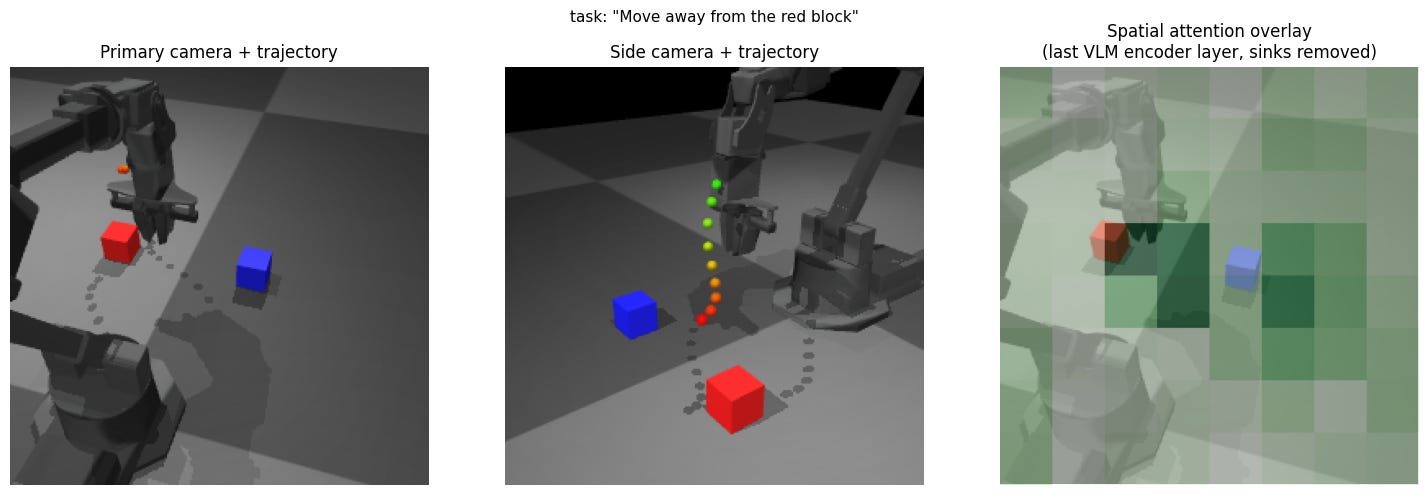
Insight: The word “away” is probably not having the spatial effect that it should in this context, exposing the ambiguity inherent in using language for robot programming. Whether we like it or not, at least unless the language model is huge, it is safer to assume that the prompt effectively indexes or extrapolates among training data, and that positional prepositions (commonly used by humans to communicate spatial commands) are not reliable to use.
What the experiments reveal about current VLAs
1. Camera view is tied to the behavior, not a calibrated parameter.
Experiments 2, 3, 4, and 5 collectively show that the model’s spatial behavior is tied to the training distribution’s camera geometry rather than to a camera-pose-invariant object representation. Swapping shoulders changes reach distance; replacing the over-shoulder view with a side view breaks the policy entirely even though the scene is identical. This is a consequence of any VLA trained end-to-end without explicit camera calibration. The practical implication is that deployment requires camera placement matching the training distribution, and the model will fail silently when out of distribution.
2. The action manifold is object-centric, not spatially general.
Experiments 7, 9, 10, and 11 collectively show that the model has no spatial primitive vocabulary independent of objects. “Move up/forward/back” all produce similar grasping-like motions; “don’t move” produces motion; “move away from block” produces motion toward the block. “Move toward/away from base” works only because the base is a visually grounded object in the scene. This generalizes beyond X-VLA: any VLA at this scale trained predominantly on pick-and-place demonstrations will have an action manifold that approximates “move toward salient object and grasp.” Spatial relation commands only work when they can be reduced to object identity. This has a direct safety implication: you cannot issue a recovery command (”stop,” “move away,” “back off”) and expect it to override the trained behavioral prior.
3. VLAs at this scale appear to lack compositional generalization.
Experiments 7, 9, and 11 show that novel combinations of spatial primitives and objects (even using vocabulary the model demonstrably knows) produce behavior dominated by the training distribution rather than the instruction. This is distinct from the question of whether larger VLAs generalize better, which is likely true, but out of scope for this article. But it does suggest that for sub-1B parameter VLAs, natural language commands are most reliable when they closely match the task distribution the model was trained on, which significantly narrows the practical definition of "zero-shot generalization" for deployment.
Closing thoughts
For flow-matching VLAs like X-VLA, the classical debugging question “is this a vision problem or a control problem?” is not just difficult to answer but structurally unanswerable. End-to-end training eliminates the interfaces that would make the question meaningful.
The debugging ideas presented here offer partial remedies: passive inspection via attention visualization and active intervention via camera ablations and language variation. These experiments also surfaced three concrete findings: spatial understanding is tied to training-distribution camera geometry rather than calibrated object pose; the action manifold is object-centric and lacks spatial primitive vocabulary; and compositional generalization breaks down for novel combinations of known concepts. These are echoes of the reliability concerns of consistency, robustness, predictability, and safety that are crucially important to evaluate robotics progress.
None of this diminishes what VLAs actually deliver — flexible task programming and meaningful robustness to environmental variation, without any robot-specific programming. The path to reliable deployment is augmenting the strengths of VLAs with explicit interfaces for safety constraints, reducing complexity by utilizing known tools for camera and kinematics calibration, and out-of-distribution detection.
In the next part, we will close the loop with this demo’s action outputs to try and leverage the strengths of VLAs in conjunction with low-level control ideas from parts 1 and 2.
If you liked this kind of analysis, please subscribe for future posts, and thanks for reading!
In fact, as mentioned above, the trajectory start point being slightly variable makes me suspect some error but it’s quite difficult to narrow down further, even after checking the documentation and opening an issue. However, this isn’t a fundamental VLA issue and I’m going to put it aside for this article.
Great article Avik. Surprised at the "Don't move" results. I'd like to extend your framework to some of the other models you mentioned. I've started with pi0, OpenVLA(-OFT), and Cosmos Policy. Would love to collaborate if that's interesting to you!