
The Loops and Hierarchies of Embodied Intelligence
Can we get embodied intelligence by connecting cameras and motors to an AI brain?

The terms “embodied intelligence”, “physical intelligence”, or “physical AI” are appearing in press releases and technical articles very often these days, but they may be referring to different things.
On one end of the spectrum, organizations are building AI brains using foundation models (principally VLAs at the moment), and deploying them to humanoid robots or robot arms for some tasks. Taking a term the public understands (artificial intelligence), and extending it to physical work via robotics, is being referred to as embodied or physical intelligence. For example, Physical Intelligence is the literal name of one of the forerunning organizations, Embodied AI is a labeled a priority in the CCP’s 15th Five-Year Plan for China’s socioeconomic development, etc.
On a different end of the spectrum, DARPA sent out a call (submissions due on the date this article is published!) to researchers requesting information about physical intelligence, referring to intelligent materials that implement sensing and actuation without needing any brain at all.
These apparently contradictory viewpoints are just the tips of the iceberg of a rich corpus of literature about embodied intelligence. In this article, we’ll review a bit of that history and then see if it can help us build better robots today.
This post may be truncated in email form — click on “View entire message” to view it in a browser.
A Brief Review of Embodied Intelligence
While approaches differ, it’s an uncontroversial opinion that having a physical instantiation (a body) is helpful to developing intelligence. Even the most practically-motivated robotics companies are drawing inspiration from comparative psychology:
A classic experiment in 1963 was conducted to investigate how vision and motor activity are linked in perceptual development. In the setup, kittens were placed in a carousel — some walking freely, others carried in harnesses. Though all of them saw the same scenes, only the active kittens developed normal depth perception. The study showed that motor activity plays a decisive role in visually guided perception and motor learning.
Robots with embodied intelligence learn in much the same way. When they move, probe and act, sensory input can be connected to the consequences of their own behaviour. This feedback allows them to build more accurate internal models.
This says that at least the development of intelligence requires having a body. Technically, after the “accurate internal models” are built, maybe you have a fully developed AI brain that can then function without that body. There are stronger views that the body can never be separated from the brain, that it is a constitutive part of intelligence.
I’ll go over some of the viewpoints along this spectrum below. If I missed an important reference, please comment below — it would help me as well as other readers!
Gibson’s Affordances (1979)
Gibson’s seminal book claims that perception isn’t a passive process, but of action possibilities (“affordances”) relative to a particular body.
The basic assumption is that vision depends on the eye which is connected to the brain. The author suggests that natural vision depends on the eyes in the head on a body supported by the ground, the brain being only the central organ of a complete visual system. When no constraints are put on the visual system, people look around, walk up to something interesting and move around it so as to see it from all sides, and go from one vista to another.
As an example, a step affords climbing for a human leg but not for a mouse. The “climbability” is a coupled property of the body and the environment. Gibson’s view goes further that the animal perceives the affordance directly, immediately and without reconciliation with an internal model in the brain.
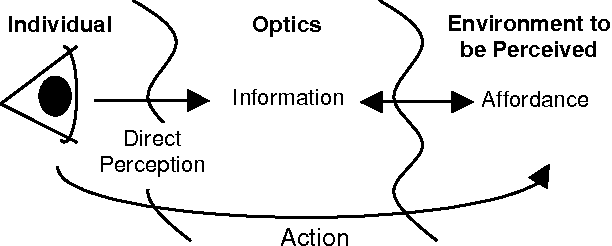
The takeaway here is that affordances inseparably tie any notion of intelligent perception to the actual sensor itself. You can’t move a “perception skill” from one embodiment to another because that changes the affordance structure.
Brooks’ Subsumption Architecture (1987)
Rodney Brooks’ 1987 paper “Intelligence Without Representation” showcases a couple of interesting concepts.
Conventional AI at the time utilized a centralized Sense → Plan → Act pipeline, a hierarchy of components performing separate functions. Instead, Brooks suggests a hierarchy by objective, where each component does all the sensing, planning, and acting it needs. For example, a component could be avoid_collision, and a second component could be move_to_goal. Each of these components has their own objective, and can take precedence over or “subsume” another.
The second concept is (as the article title suggests) a complete rejection of internal models and representations. Brooks insists that the world is the model, and the only way to develop autonomous functions is by directly interacting with the environment.
The important takeaway for us is that there is no brain at all. The body (comprising sensors, motors) is the cognitive system. This concept resulted in autonomy in a variety of robots built by Brooks and colleagues:

The other takeaway (which we will return to) is that algorithms can be distributed in parallel in different parts of the body. For examples, a small loop including only the distance sensors and a component of the motor commands would serve the obstacle avoidance function.
Predictive Coding (1999)
This seminal work by Rao and Ballard provides a neuroscientific foundation for internal “world” models. The initial 1999 paper focused on perception in the visual cortex, and is the largely accepted hypothesis for this process:
Rao and Ballard implemented a simple model of the visual cortex, using a 3-layer hierarchical neural network (they numbered the layers 0, 1, and 2) with two-way connections: predictions flowed from the higher to lower layers and errors, or residuals, went from lower to higher layers.
…
Rao and Ballard found that their network spontaneously discovered hierarchical processing: layer 1 learned to recognize bars and edges, while layer 2 (the topmost layer) learned to compose features learned by layer 1 to recognize more abstract features.
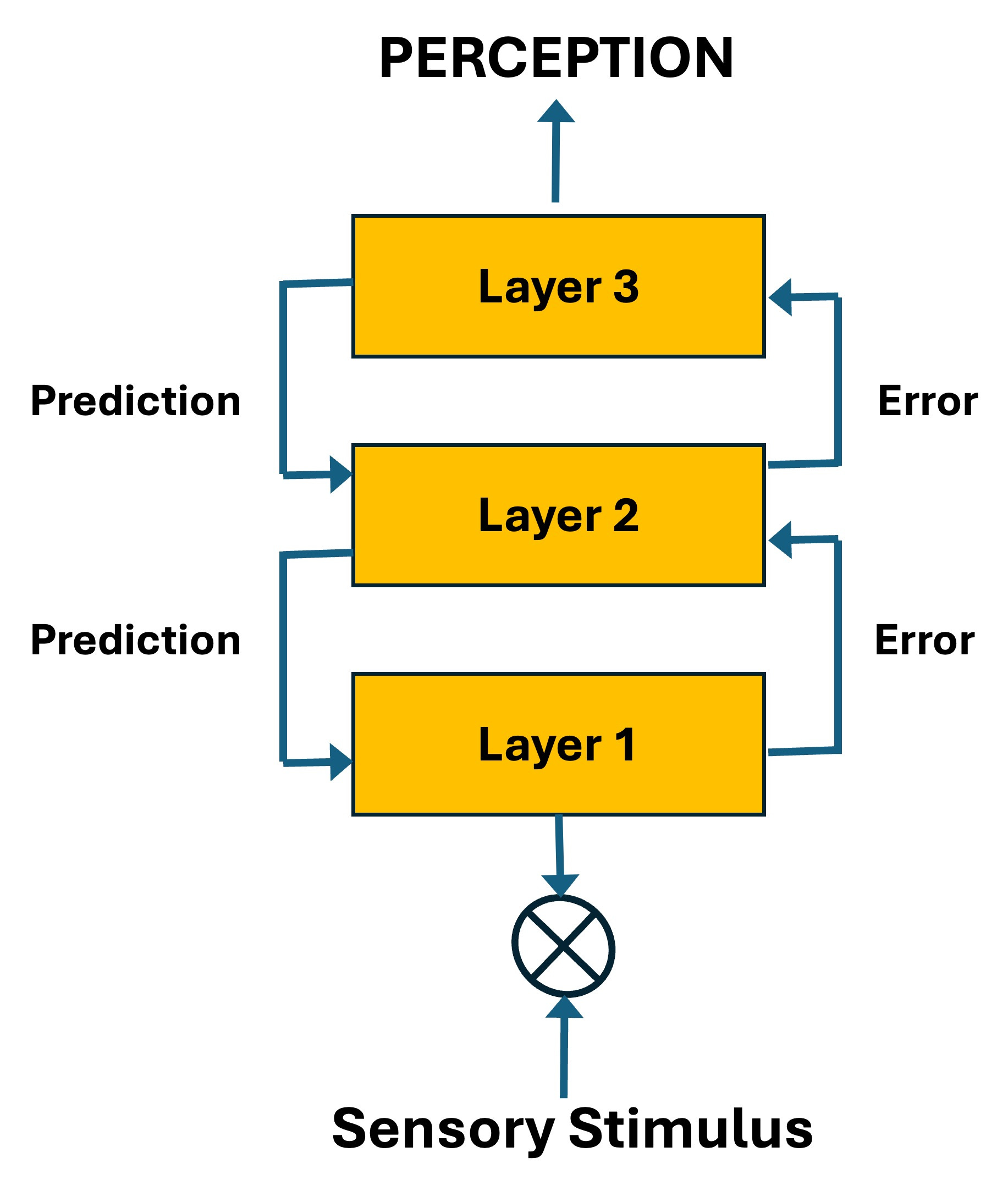
The first takeaway is that neither direction (eyes to brain, or brain to eyes) stands on its own. The prediction arrows justify world models that are currently under active research in AI and robotics, and the sensory stimulus arrows similarly justify that perceptual models in the brain don’t work without the sensors themselves.
The second takeaway here is the central role of a “brain,” which is a departure from Gibson or Brooks. Still, the necessity for a brain does not reduce the significance of the body (and the brain’s coupling to it) in this view.
Friston’s Free Energy (2006)
Friston extended the predictive processing idea from perception to action, and a broader principle for the working of the brain. Per this theory, the brain optimizes a free-energy which approximately contains terms related to prediction error (similar to above) and also value (attaining a goal).
It is easy to illustrate with an example of an arm asked to point to a green dot:

The steps in the loop are:
Brain predicts (“dreams”) sensory state: arm is at green circle
Sensor reports: arm is at red circle → prediction error
Action is triggered to make the prediction true → the arm moves
When the arm reaches green, sensor input matches prediction. The prediction error goes to zero, and free energy is minimized.
The takeaway here is that free energy crucially depends on both the perception and action systems, and is meaningless without them. The brain’s functioning cannot be separated from the body.
Mechanical Intelligence or Body Schema
Commonly, we think of a single holistic brain interfacing with all the sensors and controlling all the motor functions in an animal. Brooks’ subsumption architecture, and to some extent Gibson’s view, allowed for a more distributed notion of computation.
Computation can be embedded in parts of the body without requiring the brain to be involved. In the 2005 book How the Body Shapes the Mind Gallagher describes the concept of a “body schema” which operates without any conscious activity of the brain.
My body schema is what arranges that my hand shape itself just so in order to pick up a pencil without my paying any attention to how it is shaped, it is what tightens my back muscles and adjusts my posture when I shake hands so that I do not throw myself off balance with the movement, and so on. It operates (to a first approximation) independently of what I think or how I feel.
Reflexes or preflexes are also examples of this kind of mechanical intelligence or passive dynamics. Computers don’t always need to be built with chips, sometimes tendons and muscles can implement PID control!
In the history of robotics, some of the most exciting milestones in robotic mobility made use of this kind of mechanical intelligence. This includes Tad McGeer’s completely unpowered walkers (~1990),
the first outdoor running robot, RHex (~1999), the IHMC OutRunner running robot (~2014),
the ATRIAS robot (~2015) and its modern descendants at Agility Robotics, etc.
There’s a lot more to say about mechanical intelligence (general purpose vs. task-specific design, power amplification, latching mechanisms, etc.) that I plan to cover in a dedicated future article — subscribe to make sure you don’t miss it!
The takeaway for this article is that computation need not always go through a central brain. Hierarchically distributed mechanical intelligence can complement a brain, as it surely does for animals, reducing the burden of the nervous system:
 fish swims upstream behind an obstacle")
Returning to the DARPA Physical Intelligence RFI, it is clear that this type of distributed intelligence is what they are looking for:
Rather than relying on centralized processors and large data flows, DARPA is exploring materials that can perform computation directly.
Returning to the Present
With the practically motivated goal of utilizing the best technology at our disposal to build the most capable robots, which of these (potentially conflicting) ideas should we bring along?
Behavior Cloning and Multi-Robot Brains
Behavior cloning (imitating a human performing a task with a robot) is the de facto methodology for modern humanoid robotics. Data of humans doing a huge variety of tasks is plentiful and readily available.
This paradigm runs into some challenges in light of the embodiment theories we just discussed:
Mechanical intelligence is invisible in the dataset. If the body is performing stabilization effectively, the data only contains the stable configuration without any indication of the act of stabilization itself. This is one of the reasons VLA actions typically have some stability structure wrapped around them (like an impedance controller). It isn’t possible to directly learn a complex dynamical behavior like gymnastics purely from imitation (the next section discusses how this is actually done).
When training data is from even a very slightly different body, the Gibsonian view is that the affordances aren’t compatible. In fact, we do see that small-scale VLAs are actually quite poor at cross-embodiment generalization. Scale and cross-embodiment training show promising results, but have an efficiency cost — for a fuller coverage of this topic, check out my previous article on multi-robot brains.
Insects and elephants both walk, but they use very different types of actuators and sensors in their embodiment to do so. High-level task strategies may heavily rely on the differences in how these components work. Here is a very relevant passage from Gallagher:
At the age of nineteen, Waterman lost all sense of touch and proprioception below his neck. As a result, he instantly lost the ability to control the affected parts of his body. Slowly, he regained the ability to walk, dress, eat, and so on, but in order to do these things he had to learn to do them in a new way: by alert conscious control of his every movement. Waterman must consciously adjust his balance when turning a corner, think about swinging his leg to take a step, make an effort to shape his hand into a position suited to gripping a mug if he wants to pick it up, and so on. As a result of this, he remains substantially disabled in his behavior. His case demonstrates that, while one’s body schema is not strictly necessary for movement, it is necessary for movement in normal human beings and necessary for fluent movement even after extensive retraining.
Waterman is, as Gallagher puts it, a man with a body image but without a body schema.
A robot certainly has a different body schema from the human demonstrating a skill, and skill transfer should expect some of the same issues.
The takeaway here is that the architecture of embodied intelligence is not just a brain in a vat puppeting a body, and includes distributed, hierarchical computing.
A Potential Resolution
Despite the incompatibilities with embodiment theories, behavior cloning across embodiments does seem to empirically work, as evidenced by the growing number of robotic foundation model demonstrations. In addition, we see highly dynamic motion transferred to robots:
That last video’s most crucial component is something we haven’t discussed yet: reinforcement learning (RL). In this step, the robot is placed in a simulation with its embodiment in its environment — all the component’s of Gibson’s affordance structure — and set loose to optimize its behavior over thousands or millions of trials.1
This combination is powerful.
The AI brain (trained without preference for a particular embodiment) provides cognitive higher-level intelligence, a menu of task-solving strategies, and examples of basic perception and motor skills. Think of it as an instruction manual, or a compendium of videos of someone playing a sport that you want to learn, say tennis.
However, if you want to actually play tennis, there is no alternative to actually using your eyes to track the ball, and using your wrists to flick the racket for a forehand. The very term “muscle memory” indicates something that cannot be transferred from demonstration. However, RL (or its model-based alternative, trajectory optimization) provides a mechanism for robots to gain such practice, with its body, in the requisite environment.
A fruitful recipe for training a robot to play tennis could include a very high-level instruction manual in the form of human demonstration, followed by extensive RL with the actual sensors, potentially including sensory modalities not even available in the demonstrations.
This also makes room for incorporating innovation in meta-materials as in the DARPA RFI — those modalities can be introduced at the RL stage, enabling rich distributed, hierarchical, and feedback-enhanced architectures.
The RFI itself is a bit pessimistic about be-all-end-all human-like form factors:
Additionally, while industry has emphasized human-like form factors designed to operate in human environments, of interest here are systems optimized for mission needs. Depending on the application, this could include designs that are smaller, larger, softer, or structurally unconventional, prioritizing performance and adaptability over familiarity.
However, there’s a lot of potential in hierarchical integration of AI brains with smart materials that can perform sensing, actuation, and computation. They may come together in a humanoid form or not (we discussed form factor diversification in robotics in this post). It just needs a bit of care in the methods used!
Thanks for reading! If you liked this post, please like (❤️ button), restack, and subscribe — it helps others find my writing.
Further Reading
In related past articles, I’ve written about the architecture of end-to-end robotics pipelines, and architectural strengths and limitations of deep neural networks. If you liked this post, these would be great reads:



For this article, I returned to these great Substack posts by other authors. Check them out too:


Astute readers will observe that domain randomization (a crucial component of RL in simulation) interferes with the affordance structure. In reality, the art is to randomize enough that the policy is robust, but not enough to span different strategies being required. As nicely stated by this ICLR 2022 paper, “With sufficient data sampled using the simulator, the agent can find a near-optimal policy w.r.t. the average value function over a variety of simulation environments.” Over-randomizing can lead to the average value function not being optimal for the actual instantiation.
Another older stab at intelligence I think is a good read (just the first chapter though) is David Marr's book, Vision, from 1987. His breakdown of understanding vision as an information-processing problem still stands up to this day and even touches upon ideas in more modern critiques like Kording's "Could a Neuroscientist Understand a Microprocessor?" There's also discussion of the motor control of a fly near the second half of the first chapter that really reminds me of Brooks' subsumption architecture.
Looking forward to your article about mechanical intelligence in the future!